如何使用 GPT Image 2:提示词、编辑与可落地流程
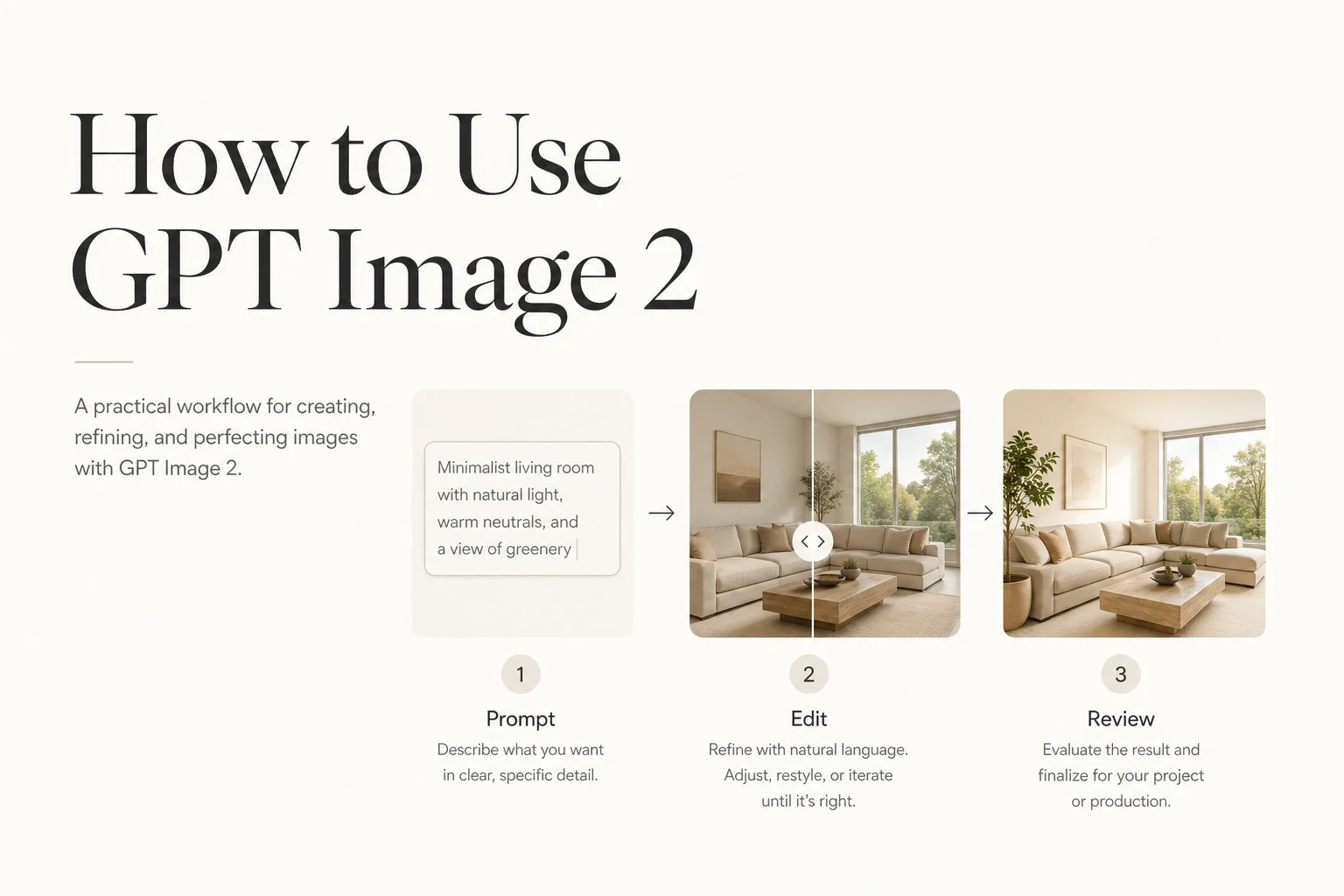
如果你搜索 how to use GPT Image 2,大多数内容只会给你一些基础 Prompt 技巧。但一旦图片真的要上线,这些远远不够。
真正困难的部分,不是生成一张“看起来不错”的图,而是生成一张真正可用的图:文字能读清、版式有层级、光线可信,而且后续修改不需要每一轮都从零开始。
这篇文章聚焦实操流程:
- 什么时候该从零生成
- 什么时候该编辑而不是重生成
- 海报、信息图、产品视觉分别怎么写 Prompt
- 结果出来后如何审图,避免把草稿直接当成成品
在 Veo 4 里, 是一个面向生产的工作流名称,用来在浏览器里调用 OpenAI 图像生成能力。需要说明的是:截至 2026 年 5 月 1 日,OpenAI 官方文档描述的是通过 Image API 和 Responses API 提供的 GPT Image 系列能力,包括生成与编辑。这个命名差异值得讲清,因为产品名和底层模型名并不总是同步变化。
简短结论
想把 GPT Image 2 用好,你要把它当成一个设计执行器,而不是魔法按钮。
先确定输出类型,再按层写 Prompt,有意识地选择生成或编辑,然后按“可发布”标准复审结果。这是最稳的路径。
最实用的默认流程如下:
| 步骤 | 先决定什么 | 默认建议 |
|---|---|---|
| 1 | 输出类型 | 海报、产品视觉、信息图、UI 板、肖像或广告素材 |
| 2 | 工作模式 | 新场景用生成;已有底图接近时优先编辑 |
| 3 | 提示词结构 | 主体、版式、风格、光线、文字、投放渠道 |
| 4 | 成功标准 | 可读性、构图、真实感、品牌匹配度 |
| 5 | 修改方式 | 每轮只修一类问题,不要整段重写 |
如果你想直接开始,可以先用 。如果你还在横向比较工具,可以看 。




