GPT Image 2の使い方:プロンプト、編集、実運用ワークフロー
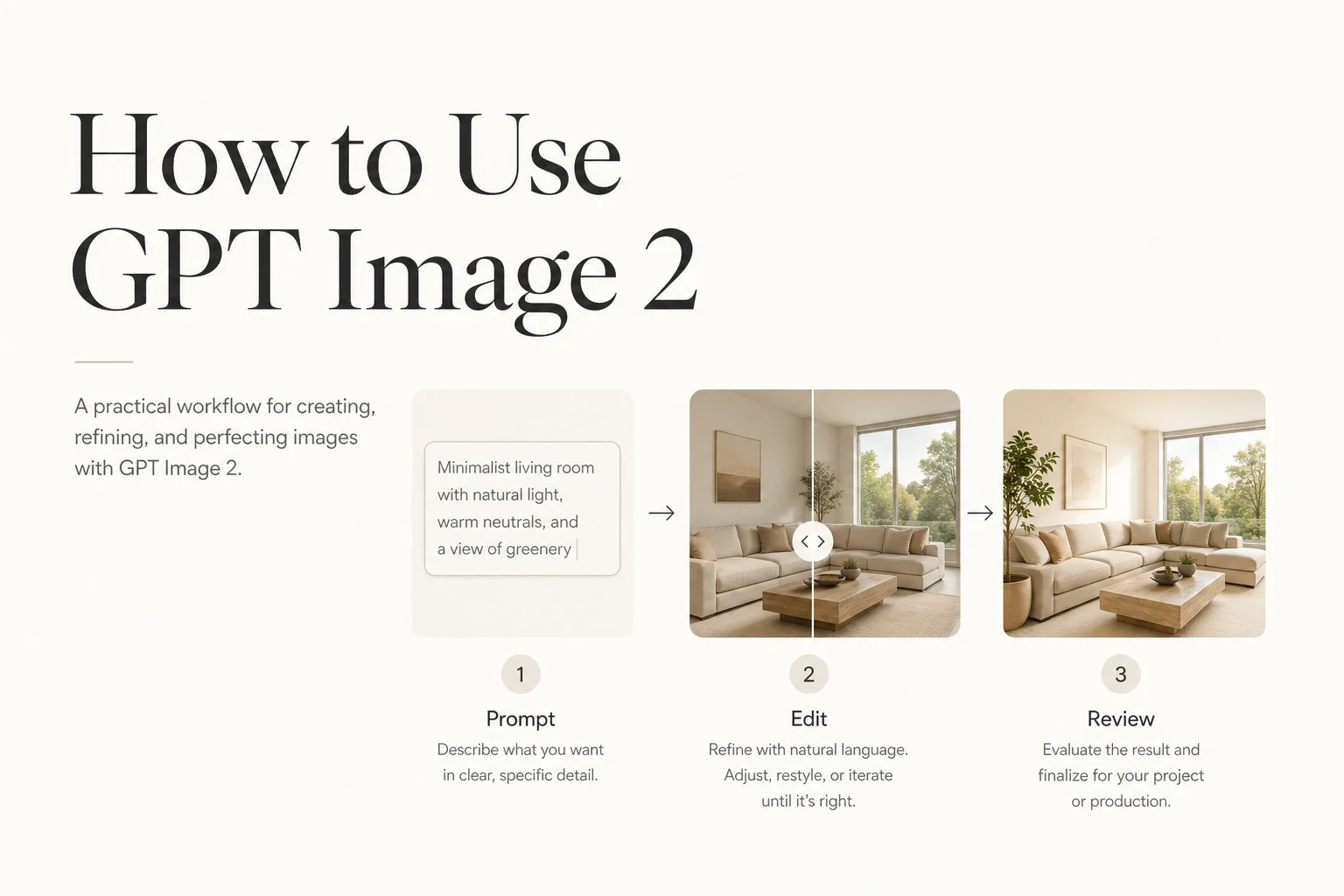
how to use GPT Image 2 を検索すると、多くの記事は基本的なプロンプトのコツだけで終わります。けれど、本当に難しいのはそこではありません。
難しいのは、見栄えのする画像を 1 枚出すことではなく、文字が読めて、レイアウトが崩れず、光も自然で、修正のたびにゼロからやり直さなくて済む「使える画像」を作ることです。
このガイドでは、実運用に必要な流れだけを扱います。
- いつ新規生成するべきか
- いつ再生成ではなく編集するべきか
- ポスター、図解、商品ビジュアルでどうプロンプトを書くか
- 結果をそのまま公開せず、どうレビューするか
Veo 4 では は、OpenAI の画像生成能力をブラウザ内ワークフローとして使うためのプロダクト名です。なお 2026 年 5 月 1 日 時点で、OpenAI 公式ドキュメントは Image API と Responses API を通じた GPT Image 系列の生成・編集機能を説明しています。製品名と基盤モデル名は必ずしも一致しないので、この整理は重要です。
最短の答え
GPT Image 2 をうまく使いたいなら、魔法のボタンではなく、デザインの実行者として扱うべきです。
出力タイプを先に決め、レイヤーごとにプロンプトを書き、生成か編集かを意図的に選び、公開基準でレビューしてください。
最も安全な流れは次の通りです。
| ステップ | 決めること | 無難な初期値 |
|---|---|---|
| 1 | 出力タイプ | ポスター、商品ビジュアル、図解、UI ボード、ポートレート、広告素材 |
| 2 | 作業モード | 新規シーンは生成、土台が近いなら編集 |
| 3 | プロンプト構造 | 被写体、レイアウト、スタイル、光、文字、掲載チャネル |
| 4 | 成功条件 | 可読性、構図、リアリティ、ブランド適合 |
| 5 | 修正ループ | 1 回の修正で 1 種類の失敗だけ直す |
すぐ試したいなら から始めてください。ツール比較も必要なら が役立ちます。




