veo 4
Loading your next page...
Preparing layouts, sections, and account state.
veo 4
Loading the next page...
Preparing pricing, articles, and creator-facing sections.
Veo 3.1 vs Seedance 2:2026年AI视频生成终极对决 | 博客
veo 4 博客 Veo 3.1 vs Seedance 2:2026年AI视频生成终极对决 Veo 3.1 vs Seedance 2:2026年AI视频生成终极对决
2026年初,AI视频生成领域经历了翻天覆地的变化。在这个快速发展的领域中,两款模型脱颖而出:Google在一月更新的Veo 3.1 (凭借突破性的4K能力震撼业界)和字节跳动在二月发布的Seedance 2.0 (搭载革命性的多模态输入架构)。两者都代表了当前AI生成视频的巅峰水平,但它们解决同一创意挑战的方式却截然不同。
这篇深度横向评测将从创作者、开发者和商业用户最关心的每一个维度,对这两款领头羊模型进行全方位解析。文章覆盖技术规格、真实性能、定价结构以及实际应用案例,为您提供决策所需的关键信息。
在深入技术细节之前,我们的研究结果如下:
Veo 3.1 的优势在于:
分辨率与画质 :业界首个支持原生4K(3840×2160)输出电影级质感 :广播级输出标准专业色彩与光影 :符合物理规律的光照与专业色彩科学原生音频生成 :同步生成对话、音效和背景音乐成熟的生态系统 :依托Google Cloud的完善API支持
Seedance 2.0 的强项在于:
创意掌控力 :强大的多模态输入(文本+图片+视频+音频)灵活性 :单次生成支持最多12个参考文件速度 :比前代产品快30%原生2K分辨率 :原生支持2048×1152分辨率面部表情与口型 :卓越的表情细腻度与多语言口型同步
选择哪个模型并非在于绝对的“更好”,而在于哪个更契合您的具体工作流、创意需求和生产目标。
了解每个模型的技术能力是做出明智选择的基础。以下是Veo 3.1与Seedance 2.0在关键规格上的对比:
功能特性 Veo 3.1 Seedance 2.0 最大分辨率 4K (3840×2160) 通过放大技术 原生 2K (2048×1152) 基础分辨率 1080p (1920×1080) 1080p (1920×1080) 视频时长 单次生成最长8秒 单次生成最长20秒 帧率 24fps (电影标准) 24fps 标准 输入模态 文本,最多4张参考图 文本,9张图,3段视频,3个音频 (共12个) 音频生成 原生同步音频 (对话、音效、音乐) 原生音频,支持节拍同步 (Beat-sync) 画面比例 16:9, 9:16 (原生竖屏), 1:1 16:9, 9:16, 1:1, 自定义 API 可用性 官方 Google API (Vertex AI, Gemini API) Jimeng AI 限量内测 生成速度 标准: ~60-90秒; 快速: ~30-45秒 ~45-60秒 (比v1.5快30%)
Veo 3.1在2026年1月不仅登上了头条,更通过支持真正的4K输出,确立了其在主流AI视频生成模型中的地位。这代表了视觉保真度的巨大飞跃,使得AI生成内容得以进入以往无法触及的专业应用领域。
通过Google Flow、Gemini API和Vertex AI提供的4K放大功能,Veo 3.1能够输出3840×2160像素的视频——这是标准1080p分辨率的四倍。这种细节水平使Veo 3.1非常适合高端应用场景,包括电视广告、数字广告牌、影院映前广告以及对画质要求极高的优质YouTube内容。
除了像素数量,Veo 3.1 在“电影级画质”上的表现也很突出。该模型输出的视频具有专业的色彩科学、模拟真实物理的复杂光照、自然的运动模糊和胶片般的质感。在当前的 AI 视频模型中,Veo 3.1 凭借电影标准帧率和专业色彩科学,能稳定产出接近广播级要求的画面。
Seedance 2.0则采取了不同的策略,提供原生的2K分辨率(2048×1152像素)。虽然在像素上不及Veo 3.1的4K,但2K相比标准1080p已有显著提升,对于大多数数字应用(包括社交媒体、网络内容和标准视频制作)来说绰绰有余。该模型通过卓越的细节渲染来弥补分辨率的差距,特别在产品展示中,纹理、Logo和包装的还原度令人印象深刻。
Seedance 2.0 在绝对分辨率上的不足,在其他画质维度上得到了补偿。它在面部表情和角色动画方面的优势非常明显,角色神态更自然,机器感更弱。
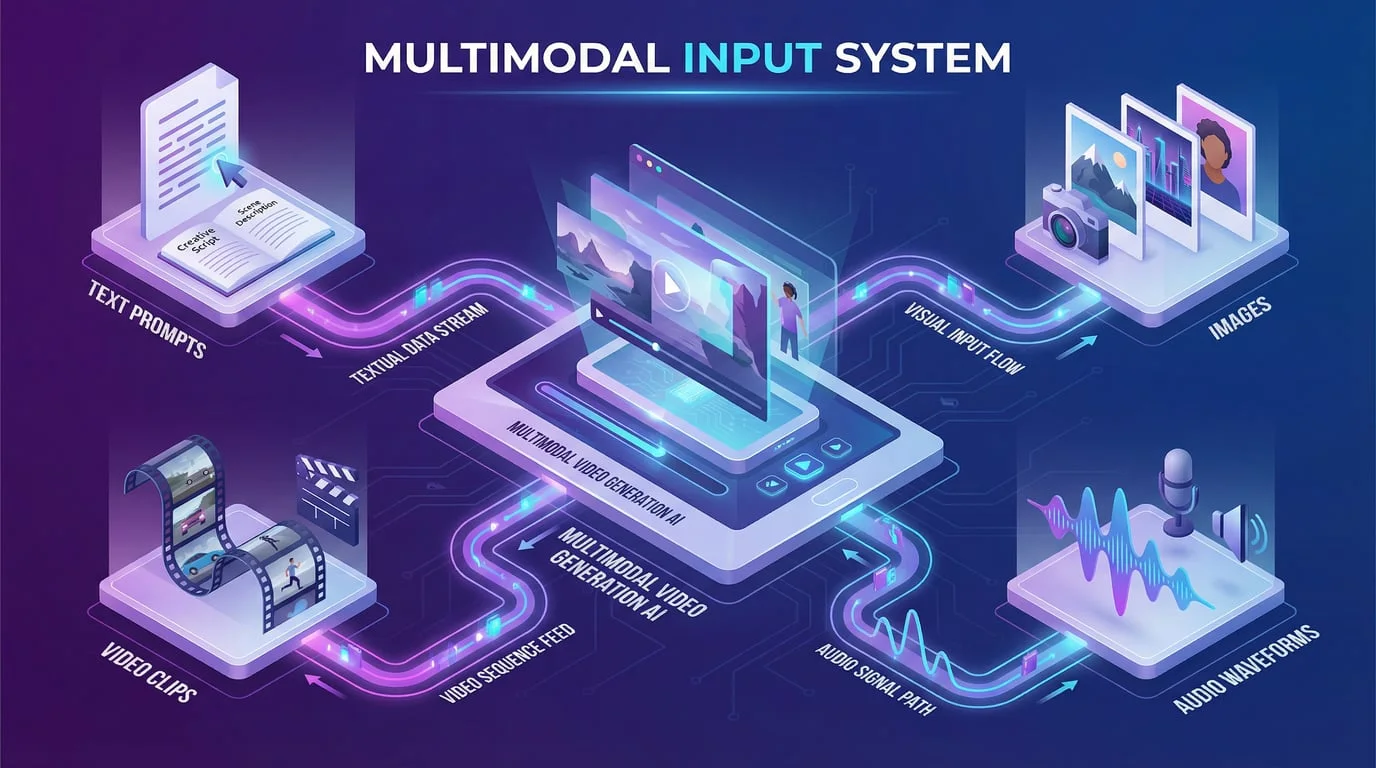
Seedance 2.0最重大的创新在于其多模态输入架构 ——这是创作者与AI视频生成工具交互方式的根本性转变。不同于仅依赖文本提示或单一参考图,Seedance 2.0允许同时接受四种不同类型的输入:文本描述、最多9张图片、3段视频素材和3个音频文件,单次生成总计可支持12个参考文件。
这种多模态方法将视频生成过程从“描述你想要的”转变为“展示你想要的”。该模型使用创新的“@提及”系统,允许创作者精确指定每个上传素材的用途。你可以在一次生成中,引用一张图片中特定角色的脸,复制一段视频中的运镜方式,匹配一段音频的节奏,并指定一个整体的风格参考。
这种架构的实际意义非凡。一个制作产品视频的营销团队可以上传产品照片、展示预期运镜的参考视频、品牌音乐以及文本描述——然后得到一个融合了所有这些元素的连贯视频。制作MV的内容创作者可以提供艺人照片、编舞参考片段、实际音轨和场景描述来生成同步内容。这种控制力在上一代模型中是不可能实现的。
Veo 3.1采取了更精简的路线,通过其“素材转视频 (Ingredients to Video)”功能,单次生成接受最多4张参考图片。虽然灵活性不如Seedance 2.0的12文件系统,但它提供了一种不同的精度。该模型在保持场景变换中的角色一致性方面表现出色——解决了角色外貌在镜头间发生微妙变化的“身份漂移”难题。系统确保角色的面部、服装和身体特征在不同场景中保持一致,这对于叙事内容至关重要。
Veo 3.1还提供独特的“帧转视频 (Frames to Video)”插值工具,允许创作者提供起始帧和结束帧,AI将生成符合两帧光照和物理规律的电影级过渡。这种首尾帧控制模式目前在主流AI视频模型中仍是Veo 3.1独有的。
音频是现代AI视频模型与前代产品最大的区别之一。Veo 3.1和Seedance 2.0都能原生生成音频,但两者解决问题的角度不同。
Veo 3.1 的集成音频生成功能在单次模型处理中就能创建包括对话、音效和背景音乐在内的同步音轨。这种统一的视听生成确保了观众所见即所闻的完美时间对齐。系统对上下文理解足够深刻,能生成恰当的声音——配合角色步态的脚步声、符合环境的背景噪音以及烘托视觉情绪的音乐。对于开发者场景,Veo 3.1 依托 Google API 与原生音频生成能力,仍然处于领先位置。
Veo 3.1这种方法的实际优势在于生产工作流。对于制作视听一致性要求高的内容(如广告、带画外音的社交媒体内容或叙事短片)的创作者来说,原生音频生成每个项目可以节省数小时的后期制作时间。音频不再是后期添加的附属品;它是在充分感知视觉内容的基础上生成的,从而实现了大多数后期流程难以达到的紧密同步。
Seedance 2.0则通过其基于参考的音频系统 采取了不同的路径。该模型不基于场景理解从零生成音频,而是接受音频文件作为输入,并同步视频生成以匹配音频的节奏、情绪和时机。这对于音乐视频、舞蹈内容或任何音轨已预定且视频需精确匹配的场景尤其强大。
该模型的“节拍同步 (Beat-sync)”功能分析上传的音频,生成的视频在动作、剪辑和视觉元素上都与音乐节奏对齐。结合其理解特定语言嘴型(音素视位)并生成准确唇部动作的多语言口型同步功能(支持中文、英文和西班牙文),Seedance 2.0在创作数字人视频和角色驱动的内容方面表现卓越,这些场景对视听精准同步有着极高要求。
AI生成视频的可信度很大程度上取决于模型对现实世界物理规律的理解和模拟程度。物体需要具有令人信服的重量和动量,织物必须自然垂坠,流体行为应像流体,物体间的交互必须看起来合理。
两个模型在物理真实感方面都取得了显著进步,但技术路线不同。Seedance 2.0 整合了增强的物理感知训练目标,在生成过程中惩罚物理上不可信的运动。这一机制让重力、织物垂坠、流体行为和物体交互都更接近真实。
这种改进在涉及复杂运动的场景中尤为明显——舞者运动时衣物的自然飘动,水花飞溅的真实物理效果,或物体以适当的重量和动量进行交互。对于开发者和创作者来说,这很重要,因为运动真实感是决定AI生成视频能否从“有趣的演示”跨越到“生产级素材”的关键因素。
Veo 3.1 通过其电影级渲染管线来处理物理真实感,该管线强调自然的运动模糊、逼真的光照交互以及对摄像机捕捉运动方式的深刻理解。该模型 24fps 的电影标准帧率赋予了视频一种胶片质感,这让习惯于专业视频内容的观众感觉更自然。Veo 3.1 在电影级光照、纹理、运动模糊和整体胶片真实感方面表现出色。
尽管行业基准测试通常认为OpenAI的Sora 2在纯物理模拟方面处于领先地位,但Veo 3.1和Seedance 2.0都已经大大缩小了差距。对于大多数实际应用——营销内容、社交媒体视频、产品演示——两者的物理质量都已达到专业标准。
视频时长是AI视频生成中的一个关键实际限制。更长的持续时间支持更复杂的叙事,减少拼接多个片段的需求,但也增加了保持帧间一致性的技术挑战。
Seedance 2.0在这里提供了显著优势,支持单次生成长达20秒 不仅为叙事发展、复杂动作和场景推进提供了更大的空间,而且无需多次生成。该模型在这一较长时间跨度内保持了一致性,解决了AI视频中常见的角色外貌、物体细节或场景元素在中途意外漂移或改变的难题。
Veo 3.1将单次生成限制在8秒 ,这就要求创作较长内容的作者生成多个片段并将它们拼接在一起。然而,该模型通过在这8秒内卓越的一致性以及专为多片段工作流设计的工具来弥补这一限制。“素材转视频”功能改进的一致性确保了角色、背景和物体在不同生成批次间保持外观一致,使得拼接过程更加无缝。
对于专注于短视频内容(Instagram Reels, TikTok, YouTube Shorts)的创作者来说,Veo 3.1的8秒限制影响较小。该模型在2026年1月更新中发布的原生9:16竖屏支持 ,专门针对移动端优先的短视频创作。这种原生竖屏生成消除了裁剪横屏视频的需求,保留了构图控制和图像质量。
了解AI视频生成的成本结构对于评估哪个模型适合您的预算和产量至关重要。
Veo 3.1的定价因访问平台和质量设置而异。通过Google AI Pro订阅($19.99/月),基于每月信用额度计算,有效成本约为每秒 $0.16。通过Vertex AI和Gemini API的定价范围从快速版的每秒 $0.10-0.15 到标准版全质量输出的每秒 $0.50-0.75。
其“快速版 (Fast variant)”通过算法优化实现了2倍的生成速度,而质量仅有1-8%的折损,非常适合草稿迭代和高产量的社交内容。“标准版”则为最终成品输出提供最高质量。这种双层系统允许创作者通过使用快速模式进行探索和创意测试,再切换到标准模式进行最终交付来优化成本。
截至 2026 年 2 月,Seedance 2.0 的官方定价尚未公布,该模型主要通过字节跳动的即梦 AI (Jimeng AI) 平台进行限量内测。按当前市场报价口径,2K 分辨率下每 10 秒视频成本约为 $0.60,整体处于中端区间。目前在内测期间,该模型可通过即梦 AI 平台免费访问,虽然生产级 API 尚未正式推出。
对于计划进行生产部署的开发者和企业,Veo 3.1依托Google Cloud的成熟API生态系统在可靠性、文档和集成支持方面提供了显著优势。Seedance 2.0的API可用性仍然有限,尽管已有第三方API聚合平台开始提供非官方访问。
在Veo 3.1和Seedance 2.0之间的选择通常取决于具体的使用场景需求:
高端商业制作与广播内容:
Veo 3.1是明确的选择。4K分辨率能力、电影级色彩科学和专业光照使其成为目前唯一适合电视广告、影院映前广告和不允许画质妥协的高端数字广告的AI模型。其广播级输出仅需极少的后期处理即可达到专业标准。
社交媒体内容与数字营销:
两者都在各自领域表现出色。Veo 3.1的原生竖屏支持和快速生成模式使其成为针对Instagram、TikTok和YouTube Shorts的高产量社交媒体制作的理想选择。Seedance 2.0的多模态输入系统为品牌特定内容提供了更多创意控制,这对于在多个素材间保持视觉识别度至关重要。
音乐视频与节奏同步内容:
Seedance 2.0在这一类别中占据主导地位。能够上传音轨并让模型生成与节拍同步的视频,再加上多语言口型同步能力,使其成为音乐视频创作、舞蹈内容以及任何音频驱动视觉节奏场景的专用工具。
产品展示与电子商务:
Seedance 2.0增强的细节渲染擅长准确还原产品纹理、Logo和包装。多模态输入允许商家上传产品照片,通过参考视频演示预期的运镜,并快速生成专业展示内容。Veo 3.1的精准度和受控的节奏也适用于强调干净视觉和专业呈现的产品视频。
叙事故事与角色驱动内容:
Seedance 2.0的20秒时长和卓越的面部表情质量使其非常适合具有情感共鸣的叙事视频。该模型在较长片段中保持角色一致性的能力降低了多场景叙事的技术挑战。Veo 3.1在不同生成批次间的角色身份一致性也适用于叙事内容,尽管8秒的限制需要对场景序列进行更多规划。
开发者集成与自动化工作流:
Veo 3.1 的 Google API、完整文档和企业级可靠性,使它成为开发者把视频生成接入应用、产品或自动化工作流时更稳妥的选择。API 的成熟度和 Google Cloud 集成也能提供生产部署所需的稳定性。
除了技术规格,真实的用体验提供了这些模型在实际生产环境中表现的宝贵见解。
Veo 3.1 的画质和电影感非常突出。4K 放大功能开启了 AI 生成视频在以往因分辨率限制而无法进入的专业领域的新用例。输出整体更接近专业成片,所需后期处理少于竞品。原生音频生成在上下文匹配上也更自然,但音频质量仍会随场景复杂性波动。
Seedance 2.0 因其多模态控制系统获得了很高关注。它把视频生成从“可演示”推到了“可落地”的阶段。面部表情质量尤其突出,角色动画比多数竞品更自然,机器感更弱。
生成速度是生产工作流中的实际考量。Seedance 2.0比前代产品快30%的速度意味着更快的迭代周期,这在探索创意方向或生成大量内容时意义重大。Veo 3.1的快速模式提供了类似的速度优势,尽管是以1-8%的画质折损为代价。
两个模型仍会出现AI视频生成常见的伪影和错误——物理违规、时间不一致或意外的视觉元素。然而,这些问题的频率和严重程度相比早期模型已大幅下降。对于大多数用例,错误率已降至不妨碍生产使用的阈值以下。
虽然本文通过对比聚焦于Veo 3.1和Seedance 2.0,但在更广泛的竞争格局中定位它们能提供有价值的背景。OpenAI的Sora 2 仍然是纯物理真实感的基准,当物体需要以令人信服的物理精度进行交互时,它是首选。快手的Kling 3.0 提供原生4K 60fps以及出色的运动质量和免费层级,这对注重成本的创作者极具吸引力。
许多专业制作团队策略性地使用多个模型——用Seedance 2.0进行基于模板的工作和需要多模态控制的内容,用Veo 3.1制作需要4K分辨率的最终高质量交付物,并利用其他模型发挥其特定优势。竞争格局已经成熟到模型选择成为一种战略工作流决策,而非寻找单一“最佳”选项的过程。
了解Veo 3.1和Seedance 2.0的能力只有在您能有效访问和使用这些模型时才有价值。Veo4.im 提供了一个统一的平台,可以便捷地访问多个尖端视频和图像生成模型,消除了管理多个API集成和访问点的复杂性。
该平台允许创作者、开发者和企业使用前沿AI模型,而无需直接API集成的技术开销。这种统一访问方式意味着您可以针对特定用例测试不同模型,根据项目需求在它们之间切换,并优化您的工作流,而无需被锁定在单一供应商的生态系统中。
对于正在评估哪个模型最适合其生产需求的团队,通过单一界面访问多个选项极大降低了对比测试的摩擦。您可以跨不同模型使用相同的提示词生成内容,并排比较结果,并基于实际输出而非理论规格做出明智决策。
在Veo 3.1和Seedance 2.0之间做出选择,需要根据您的具体需求在几个维度上进行评估:
最大分辨率至关重要(广播、电影或高端数字的4K需求)
电影级画质和专业调色不可妥协
带有上下文声音设计的原生音频生成很有价值
您需要具有企业级可靠性的成熟API生态系统
社交媒体短视频(竖屏)是您的主要关注点
预算允许支付更具溢价的价格(全质量每秒 $0.50-0.75)
通过多模态输入的创意控制对您的工作流必不可少
您需要整合特定的音轨、参考视频或多个风格指南
更长的单次生成时长(20秒 vs 8秒)能降低制作复杂性
面部表情质量和角色动画至关重要
音乐视频、舞蹈内容或节奏同步视频是您的重点
2K分辨率满足您的质量要求
您看重更快的生成速度和迭代周期
您运营着包含多样化内容类型的生产业务
预算允许根据用例策略性地选择模型
您希望通过在草稿阶段使用不同模型来优化成本
您的工作流能从每个模型的独特优势中受益
2026年初AI视频生成的快速演进表明,我们仍处于该技术发展曲线的早期阶段。Veo 3.1实现的4K分辨率和Seedance 2.0的多模态架构代表了重要的里程碑,但也指向了将进一步改变视频制作的未来能力。
近期的预期发展包括更长的生成时长、改进的物理模拟、延长时间跨度下更好的时间一致性、更复杂的音频生成以及能让创作者对输出有更精确影响的增强控制系统。Google、字节跳动、OpenAI及其他玩家之间的竞争压力确保了快速迭代和持续改进。
对于创作者和企业而言,这意味着现在投资理解这些工具——学习它们的优势、局限性和最佳用例——将在技术持续成熟的过程中提供竞争优势。今天开发的工作流和创意方法将随着底层模型的改进而扩展。
Veo 3.1和Seedance 2.0代表了AI视频生成中的两种不同理念,均在极高的技术成熟度上得以实现。Veo 3.1优先考虑最大视觉质量、电影级打磨和适合最苛刻用例的专业级输出。Seedance 2.0强调创意控制、灵活性以及将多个参考源整合到统一生成中的能力。
没有哪个模型是普遍“更好”的——它们在不同场景中表现出色,服务于不同的创意需求。Veo 3.1是为那些需要广播级质量并愿意在其约束下工作的创作者准备的工具。Seedance 2.0则是为那些看重控制力、灵活性以及能够像指导制作助理一样指导AI而非仅仅给它提示词的创作者的选择。
两个模型的成熟标志着AI视频生成已经跨越了一个关键门槛:从实验性技术转变为生产就绪的工具。问题不再是AI能否生成可用的视频,而是哪个模型最契合您的具体工作流、创意需求和生产目标。
如需便捷访问这些及其他前沿AI视频模型,Veo4.im 提供了一个统一平台,简化了使用多个前沿模型的复杂性,让您可以专注于创意而非技术集成。
Veo 3.1 vs Seedance 2:2026年AI视频生成终极对决
核心摘要:谁是赢家?
技术规格:参数对比
分辨率与画质:4K的统治力
多模态革命:Seedance 2.0 的杀手锏
音频生成:原生同步 vs 参考控制
物理真实感与运动质量
时长与时间一致性
定价与可访问性
场景分析:哪个模型适合什么场景?
真实性能
更广泛的竞争格局
做出决定:实用框架
AI视频生成的未来
结论:两种理念,殊途同归