veo 4
Loading your next page...
Preparing layouts, sections, and account state.
veo 4
Loading the next page...
Preparing pricing, articles, and creator-facing sections.
HappyHorse 1.0 是什么?这个神秘模型为什么冲到第一

如果你在搜索 what is happyhorse 1.0,你通常并不是在泛泛地看新闻,而是在
试图搞清楚一个非常具体的困惑。
你已经看到这个名字冲上了 Artificial Analysis 视频榜单的顶部。你也看到有人
说它是一个即将发布的开放模型、一个来自亚洲的神秘发布、一次低调提交到
benchmark 的模型,或者只是某个平台包装出来的产品标签。与此同时,围绕它的
能力描述也显得异常激进,尤其对于一个还没有正式公开发布的视频模型来说:
原生音频、多语言唇形同步、很强的文生视频、很强的图生视频,以及意外快的
生成速度。
但真正实用的答案,比这些 hype 更克制。
截至 2026 年 4 月 9 日,对
最稳妥的理解是:
它是一个与顶级 benchmark 成绩绑定在一起的神秘视频模型身份,但背后还没有
公开的官方仓库、公开权重,或者第一方技术报告来完成验证。
这正是它现在会引发如此多关注、同时又让讨论显得格外混乱的原因。
这篇文章会做四件事:
- 用当前最可辩护的方式解释 HappyHorse 1.0 到底是什么
- 说明为什么它的榜单成绩值得认真看
- 把已验证事实和外部说法分开
- 给你一个更实用的判断框架,决定现在应该关注、等待,还是暂时忽略这波热度
HappyHorse 1.0 之所以难定义,是因为公开信号同时指向了两个不同方向。
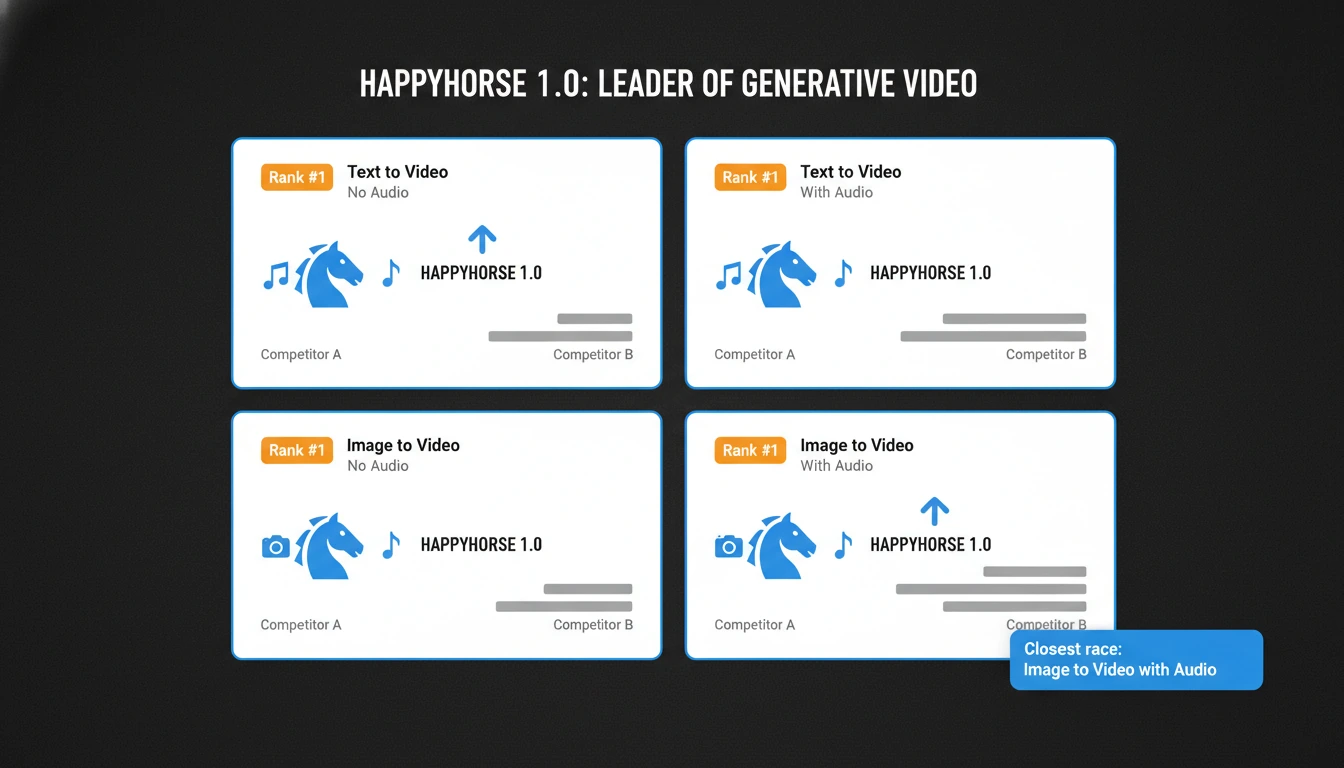
一方面,这个模型名目前在 Artificial Analysis 的公开视频榜单上,同时拿到了
text-to-video 和 image-to-video、带音频和不带音频四个主要维度的第一名。
这足以让它立刻具备“严肃前沿视频模型”的可信度。
但另一方面,它的公开发布叙事依旧很弱:
- 没有官方公开 GitHub 仓库
- 没有公开可下载权重
- 没有公开官方技术论文
- 主站 happyhorses.io 把 HappyHorse 描述成平台能力的一部分,而不是一个
可独立下载的模型产品
所以,当前最有用的工作定义是:
HappyHorse 1.0 是一个在 benchmark 上表现极强、已经拿到公开性能信号的
视频模型身份,但它还不是一个已经被完整验证的 open-weights 公共发布。
截至 2026 年 4 月 9 日,Artificial Analysis 把 HappyHorse 1.0 排在其视频
leaderboard 四个主要公开切片的第一名:
| 类别 | HappyHorse 1.0 状态 | Elo 分数 | 为什么重要 |
|---|
| 文生视频,无音频 | #1 | 1383 | 这是最直接的信号,说明在盲测投票里,用户更偏好它的纯视觉输出 |
| 文生视频,有音频 | #1 | 1229 | 即使把音频纳入比较,它也仍然领先当前公开字段 |
| 图生视频,无音频 | #1 | 1413 | 这是它最强的公开优势,暗示它在视觉控制或视觉偏好上非常突出 |
| 图生视频,有音频 | #1 | 1165 | 它仍然领先,但优势已经非常小,这一点很重要 |
Artificial Analysis 还给出了三条很多快速文章没有写清楚的信息:
- HappyHorse-1.0 被标记为 最近一个月新增到榜单的模型
- 它在榜单上的可用性状态仍然是 Coming soon
- 无音频维度已经积累了不算小的样本量,因此很难把这个排名简单归因为
小样本偶然
样本量这一点尤其关键。当前公开无音频表格里,Artificial Analysis 显示
HappyHorse 在 text-to-video 上已有 3,895 samples,在 image-to-video
上已有 11,153 samples。这不代表它的第一名就已经完全稳固,但至少说明
它不是靠一个几乎空的投票池漂在榜首。
通常,一个神秘模型会因为炫目的 demo 或者某个传闻开始走红。但
HappyHorse 1.0 之所以被持续讨论,是因为它已经在一个公开的 blind arena
里拿到了第一。Artificial Analysis 不是按照营销页面有多响亮来给模型排名,
而是通过 Elo 体系,根据相同 prompt 或相同源图下的两个结果,让用户在
不知道模型名称的情况下进行盲选比较。
这套方法并不会自动证明模型身份本身值得信任,但它会让输出质量信号变得更难
被轻易否定。
- 这个模型已经能打赢或者追平最强的一批商业视频模型
- 它在文生视频和图生视频两端都具备竞争力
- 即使把音频算进去,它仍然保持在第一梯队
- 你还不能把它当成 Wan 2.2、LTX-2 这类已经验证过的 open-weights 模型
- 你无法下载它
- 你无法审查一个真实官方 repo
- 你无法核对它的正式许可协议
- 你无法通过第一方论文确认它的架构
一个能冲到这么高排名的模型,通常会伴随着更清晰的身份。通常你会看到这两种
情况中的一种:
- 一个有明确访问方式和价格的商业产品
- 一个带权重、代码和论文的开放发布
但 HappyHorse 1.0 当前处在一个很不寻常的中间态。质量信号已经公开了,
但身份和分发信号仍然模糊。
Artificial Analysis 上的 Coming soon 标记把这个问题说得更透了。这里
不只是质量问题,也是不成熟的 访问能力问题。一个模型即使在盲测偏好上
排名第一,也可能回答不了开发者最基础的那个问题:
我今天能不能真的接入它,或者下载它?
happyhorses.io 并没有把 HappyHorse 描述成一个你可以拿走、自己运行的
公开独立开源包。它把 HappyHorse 描述成 HappyHorses 平台中的一个视频生成
能力。
- HappyHorse 是 SaaS 工作流中的一部分
- 它当前并没有被作为独立模型产品提供
- 它没有被描述成一个可下载包
- 平台明确表示,它并不声称拥有底层 AI 模型技术的所有权
Where do I download HappyHorse 1.0?
我现在看到的,到底是一个 benchmark 上夺冠的模型身份、一个面向平台的包装 标签,还是一个先通过 SaaS 产品呈现出来的内部能力?
很多快速博客在这里就写偏了。它们把 benchmark 名字和产品标签当成已经可以
无缝映射到标准公开模型发布的东西来看待。但实际上还远远没到那个程度。
理解 HappyHorse 1.0 最好的方式,是把信息拆成两列来看:
| 维度 | 当前公开可验证的信息 | 目前仍然只是报道或推断的信息 |
|---|
| 榜单状态 | 截至 2026 年 4 月 9 日,它在 Artificial Analysis 四个公开视频维度都排第一 | 随着更多投票进入,这个领先是否还能稳定维持 |
| 公开可用性 | 没有官方公开权重,也没有第一方官方 GitHub 仓库 | 未来开放发布是否会包含权重和推理代码 |
| 产品身份 | HappyHorses 官网将它视作平台能力,而非独立模型产品 | 榜单中的模型名是否会和未来独立发布一一对应 |
| 架构 | 没有第一方技术论文确认任何架构细节 | 约 15B 参数、统一多模态 Transformer、DMD 风格蒸馏、无独立音频模块等说法 |
| 音频能力 | 榜单显示它参与了音频维度评测,而且依然成绩很强 | 它具体如何生成音频,以及如何实现对齐 |
| 开源状态 | 公开 GitHub tracker 指出,官方 open-source release 还没有发生 | 精确发布时间、协议和打包方式 |
- 一类人会默认所有被宣称的能力都已经真实且可交付
- 另一类人则会因为发布叙事不清晰,就默认这一切都是假的
榜单性能信号看起来真实到足以值得关注,但发布成熟度和模型身份信号
仍然不完整,不足以让你投入高强度信任。
还有一个细节也必须放在这里讲。HappyHorse 看起来最强的是 无音频
leaderboard。一旦把音频加入比较,它的优势就明显没那么大了。换句话说,
它当前的公开声誉更像是由 视觉偏好领先 驱动,而不是一个清晰的公开结论:
它已经在音频优先的生产工作流里全面领先。
HappyHorse 1.0 会获得额外关注,还有一个原因:如果外界流传的那套能力描述
最终被证实,它确实会非常强。
- 原生联合音视频生成
- 多语言唇形同步
- 一个系统同时支持文生视频和图生视频
- 1080p 输出
- 通过蒸馏获得更快推理,而不是依赖长步数采样
- 开放发布计划不仅包含核心模型,还包含更多偏生产化的组件
如果这些能力里大部分最终都是真的,HappyHorse 1.0 会很重要,原因很简单:
它正好瞄准了当前开放视频模型仍然难以补齐的那道缺口。
这道缺口并不只是视觉质量,而是下面这些能力的组合:
- 强视觉质量
- 原生声音
- 强图生视频控制
- 实用速度
- 一个创作者真正能拿来用的发布形式
当前大多数开放或半开放的视频工作流,仍然要靠多步拼接。你先生成无声视频,
然后再补语音或音效,再修唇形同步,再调时间轴,最后努力维持画面一致性。
如果有一个模型真的能在一趟里完成其中更多环节,那它带来的会是一次实际意义上
的跃迁,而不只是又一个排行榜条目。
问题在于,公开证据还不完整。所以现在更合理的处理方式是,把这些能力说法当成
有一定可信度的设计性外部说法,而不是当成已经可投入生产的既定事实。
围绕 HappyHorse 1.0 的社区反应并不是随机的,它其实遵循了很典型的模式。
对他们来说,有没有论文是次要的。输出质量信号已经足够让他们持续盯着。
这类人期待的是一个本地或半本地可用的突破型视频模型。他们会被下面这些
可能性吸引:
- 一个新的开放视频 benchmark 第一名
- 一个带原生音频的替代路线,取代更碎片化的拼装式 pipeline
- 相比当前开放模型字段的明显升级
这种兴奋是可以理解的。开放视频在很多关键点上,尤其是音频和运动质感方面,
看起来仍然落后于最好的闭源系统。
这其实是最理性的怀疑阵营,也是最值得认真听的阵营。
- 一个模型怎么会在还没有清晰正式发布之前,就先冲到 arena 顶部?
- HappyHorse 到底是真实模型名,还是只是一个平台前台标签?
- 为什么有些公开页面像是在暗示“即将开源”,但主产品页又说它不是独立模型?
- 在真实 repo、许可证和论文都没出来前,是否应该围绕它建立工作流?
这些并不是阴谋论式的问题,它们恰恰是现在最应该问的问题。
HappyHorse 1.0 在公开 arena 偏好上,可能已经强于当前开放字段,但这 并不
意味着它和那些你今天就能下载、运行、接入的开放模型,已经属于同一个实用分类。
| 模型路线 | 公开 benchmark 位置 | 今天可下载 | 原生音频情况 | 实际意义 |
|---|
| HappyHorse 1.0 | 当前整体公开信号最强 | 否 | 有相关说法,且音频榜单表现部分暗示了这一点 | 很值得观察,但不适合重度依赖 |
| LTX-2 Pro / LTX-2.3 | Artificial Analysis 当前最强的 open-weights 路线之一 | 是 | 没有外界传闻中 HappyHorse 那么激进 | 今天就能用的真实开放工作流 |
| Wan 2.2 A14B | 强开放模型参考点 | 是 | 没有同等级的公开原生音频突破叙事 | 适合现在就做真实测试 |
| HunyuanVideo 系列 | 公开且可审查 | 是 | 更接近传统多步工作流逻辑 | 有用,但不是那种神秘跃迁 |
这也是为什么只说一句 best open video model 是不够的。
- 现在盲测偏好里最强的是哪一个模型?
- 今天我真正能严肃接入到工作流里的模型是哪一个?
HappyHorse 1.0 也许在第一个问题上最强,但在第二个问题上还不是。
而且还有第三个问题,比很多对比文章承认的重要得多:
- 哪个模型既强,又具备稳定的公开访问路径和开发者接口?
一旦你用这个条件来筛,practical leaderboard 就会和纯 Elo 排名看起来很不一样。
HappyHorse 1.0 是一个 高表现 AI 视频模型的神秘身份。它已经在公开盲测
排名环境里证明了自己的强度,但还缺乏足够完整、足够可信的发布基础设施,
因此创作者还不能把它当成一个普通的开源模型,或者一个文档齐全的商业模型来
对待。
- 这个模型值得持续关注
- 当前公开说法不足以支持盲目信任
- 你的评估重点应该放在发布成熟度,而不只是 benchmark 荣耀
这不代表你该忽视它,而是说你应该以更合理的门槛来评估它。
只有当下面这些信号公开出现之后,才应该考虑围绕 HappyHorse 1.0 建立依赖:
- 官方第一方仓库
- 真实公开权重或稳定 API 访问
- 可以评估的许可证
- 技术论文,或者至少正式技术说明
- 不只是 arena 偏好,还能重复复现的公开样例
在这之前,更合理的做法是把它当成一个持续观察对象,而不是生产级依赖。
如果你真正的需求不是继续等待一个神秘发布慢慢清晰,而是现在就测试前沿视频
工作流,那么 Veo 4 会是更安全的路线。
因为它给你的是一个实用工作空间,让你评估多条顶级视频生成路径,而不是把整条
pipeline 押在一个尚未完全确认的身份之上。
如果你正在判断现在该多认真看待 HappyHorse 1.0,可以用下面这个框架:
- 你持续跟踪前沿 AI 视频 benchmark
- 你关心原生音频生成
- 你想判断是否有新的开放或半开放 leader 正在出现
- 你能把榜单胜利和发布成熟度分开看
- 你需要一个本月就能部署的工作流
- 你需要明确许可证
- 你需要可复现的接入方案
- 你需要一个产品身份稳定的提供方
- 你只关心现在就能端到端使用的工具
- 你没有时间跟踪模糊的 pre-release 信号
- 你知道团队会对 leaderboard 新奇感反应过度
不是。截至 2026 年 4 月 9 日,没有官方公开权重发布,没有官方第一方
GitHub 仓库,也没有第一方技术论文让它成为一个标准意义上已验证的开源发布。
是的。截至 2026 年 4 月 9 日,Artificial Analysis 显示 HappyHorse 1.0 在
text-to-video 和 image-to-video、带音频和不带音频四个维度上都处于第一。
当然,随着更多盲测投票进入,具体 Elo 分数仍可能变化。
公开层面不是。HappyHorses 主站把它描述成平台里的一个能力,并明确表示它不是
一个独立模型或可下载包。
还没有。这些说法被大量重复,其中一些未来可能会被证实,但目前还没有第一方
公开技术发布,足以让严肃的开发团队把这些信息当成最终结论。
因为公开 blind preference 数据本身仍然有意义。一个模型并不需要有一套非常
干净的 PR 发布流程,才能稳定生成人们更喜欢的结果。即使产品身份仍然模糊,
输出质量信号也可能是真实的。
- 官方仓库
- 公开权重或稳定 API 访问
- 许可证
- 能让能力可审查的技术论文或正式发布说明
HappyHorse 1.0 之所以重要,是因为它做了一件很少见的事。
它先拿到了顶级公开排名,再去等待一个足够清晰的公开发布叙事。
如果你只看排名,你会过度信任它。
如果你只看发布混乱,你又会低估它。
- benchmark 信号很强
- 神秘感是真实存在的
- 能力说法确实值得关注
- 身份仍未解决
- 距离真正的生产级成熟还没走完
所以,如果你的问题是 what is happyhorse 1.0,当前最好的回答就是:
它是当下 AI 视频领域最值得关注的神秘模型,而在发布叙事追上排名之前,
它都还会是一个谜。
HappyHorse 1.0 是什么?这个神秘模型为什么冲到第一
先说结论
为什么它突然被广泛讨论
排名叙事很强,但发布叙事很弱
HappyHorses 官网实际告诉了你什么
哪些是已验证事实,哪些还只是外部说法
为什么它的能力说法听起来这么夸张
为什么评论和猜测会如此分裂
阵营一:榜单信徒
阵营二:开放模型期待者
阵营三:身份怀疑派
它和今天真正可用的 open-weights 视频模型相比如何
所以,简单说 HappyHorse 1.0 到底是什么
现在应该围绕它做构建吗
一个简单决策框架
下列情况适合重点关注
下列情况需要保持谨慎
下列情况可以忽略这轮 hype
FAQ
HappyHorse 1.0 现在是一个官方公开的开源模型吗?
HappyHorse 1.0 真的排第一吗?
HappyHorse 1.0 是一个我现在能下载的独立模型吗?
它的架构和速度说法已经被确认了吗?
如果它的身份还不清楚,为什么仍然重要?
目前最聪明的跟踪方式是什么?
最后判断