what is happyhorse 1.0 을 검색했다면, 보통은 막연한 뉴스가 아니라
아주 구체적인 혼란을 풀고 싶어서일 가능성이 큽니다.
Artificial Analysis 비디오 리더보드에서 이 이름이 갑자기 맨 위로 올라간
것을 봤을 겁니다. 공개를 앞둔 오픈 모델이라는 말도 있고, 아시아 기반의
미스터리 릴리스라는 말도 있습니다. 조용히 benchmark 에 제출된 모델이라는
추측도 있고, 단지 플랫폼 측 라벨일 뿐이라는 해석도 있습니다. 동시에 아직
공식 출시되지 않은 비디오 모델치고는 지나치게 야심차게 들리는 능력 주장도
퍼졌습니다. 원생 오디오, 다국어 립싱크, 강한 text-to-video, 강한
image-to-video, 그리고 예상보다 빠른 생성 속도 같은 것들입니다.
하지만 실무적인 답은 이런 과열된 기대보다 훨씬 절제돼 있습니다.
2026년 4월 9일 기준, HappyHorse 1.0은 최상위권 benchmark 결과와
결부된 미스터리 비디오 모델 이름 으로 이해하는 것이 가장 타당합니다.
다만 이를 뒷받침할 공식 공개 저장소, 공개 weights, 퍼스트파티 기술
보고서 는 아직 없습니다. 그래서 이렇게 많은 관심을 받는 동시에, 논의도
유난히 혼란스럽게 흘러가는 것입니다.
이 글은 네 가지를 해줍니다.
현재 기준 가장 방어 가능한 방식으로 HappyHorse 1.0을 설명한다
왜 리더보드 결과가 중요한지 보여준다
검증된 사실과 외부 주장만 있는 부분을 분리한다
지금 당장 따라가야 할지, 조금 더 기다려야 할지, 아니면 hype 를 무시해도
될지를 판단하는 틀을 제공한다
HappyHorse 1.0은 공개 신호가 동시에 서로 다른 방향을 가리키기 때문에
분류하기가 쉽지 않습니다.
한편으로는, 이 모델명은 지금 Artificial Analysis 의 공개 리더보드에서
text-to-video 와 image-to-video 양쪽 모두, 그리고 오디오 포함/미포함
카테고리까지 포함해 최상위에 올라 있습니다. 그것만으로도 frontier 급
비디오 모델 후보라는 신뢰를 얻기에 충분합니다.
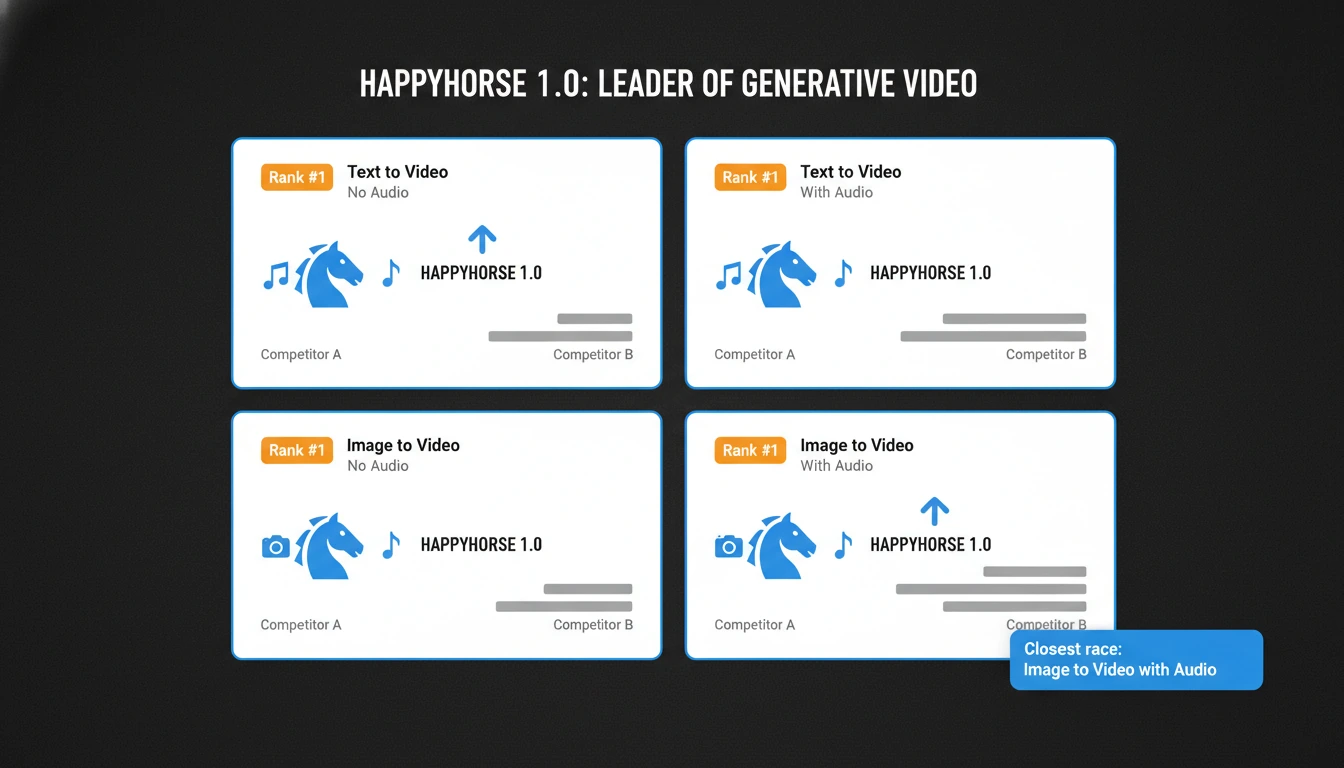
2026년 4월 9일 기준 Artificial Analysis 는 HappyHorse 1.0을 자사 비디오
리더보드 시스템의 네 가지 주요 공개 슬라이스 모두에서 1위로 표시합니다.
카테고리
HappyHorse 1.0 상태
Elo 점수
중요한 이유
Text-to-video, 오디오 없음
#1
1383
블라인드 투표에서 순수 비주얼 출력이 선호된다는 가장 분명한 신호다
Text-to-video, 오디오 포함
#1
1229
오디오가 포함돼도 현재 공개 필드를 앞선다
Image-to-video, 오디오 없음
#1
1413
가장 큰 공개 우위이며, 비주얼 제어 또는 시각적 선호도가 특히 강하다는 뜻일 수 있다
Image-to-video, 오디오 포함
#1
1165
여전히 앞서지만 차이는 매우 작고, 바로 그 점이 중요하다
Artificial Analysis 는 많은 빠른 요약 글이 놓치는 세 가지 정보도 함께
보여줍니다.
HappyHorse-1.0은 최근 한 달 사이 리더보드에 추가된 모델 로 표시된다
공개 가용성은 일반 live API 제공이 아니라 Coming soon 으로 적혀 있다
오디오 없는 슬라이스에는 이미 무시하기 어려운 수준의 표본이 쌓여 있어,
소표본 우연으로 치부하기 어렵다
특히 표본 수는 중요합니다. 공개된 no-audio 테이블에서 Artificial Analysis 는
HappyHorse 에 대해 text-to-video 는 3,895 samples, image-to-video 는
11,153 samples 를 보여줍니다. 이것이 순위를 영구히 고정한다는 뜻은
아니지만, 거의 비어 있는 투표 풀 위에 우연히 떠 있는 상황은 아니라는 뜻입니다.
이건 흔한 hype 사이클이 아닙니다.
보통 미스터리 모델이 뜨는 이유는 화려한 데모나 루머 때문입니다. 그런데
HappyHorse 1.0은 이미 공개 blind arena 에서 최고 자리를 차지했기 때문에
주목받고 있습니다. Artificial Analysis 는 시끄러운 마케팅 페이지로 모델을
순위 매기지 않습니다. 같은 prompt 나 같은 source image 에서 나온 두 결과를,
모델명을 가린 채 비교하는 blind comparison 을 바탕으로 Elo 를 계산합니다.
이 시스템이 모델 정체성을 자동으로 신뢰 가능하게 만들지는 않지만, 적어도
출력 품질 신호 자체를 무시하기는 훨씬 어렵게 만듭니다.
아직 Wan 2.2 나 LTX-2 같은 검증된 open-weights 모델처럼 다룰 수 없다
다운로드할 수 없다
공식 repo 를 감사할 수 없다
공식 라이선스 조건을 확인할 수 없다
퍼스트파티 논문으로 아키텍처를 검증할 수 없다
이 간극이 바로 댓글이 기대와 의심 사이에서 갈리는 이유입니다.
이 정도로 높은 순위를 차지하는 모델이라면 보통 더 명확한 정체성을 갖고
등장합니다. 일반적으로 기대하는 것은 둘 중 하나입니다.
접근 방식과 가격이 문서화된 상용 제품
weights, 코드, 논문을 갖춘 오픈 릴리스
HappyHorse 1.0은 지금 이 둘 사이의 드문 중간 상태에 있습니다. 품질 신호는
공개돼 있지만, 정체성과 배포 신호는 아직 흐립니다.
Artificial Analysis 의 Coming soon 표시는 이 점을 더 선명하게 보여줍니다.
이 이야기는 단지 품질만의 문제가 아닙니다. 접근 성숙도의 부재 문제이기도
합니다. 모델이 blind preference 에서 1위를 해도, builder 팀이 가장 먼저
묻는 질문에는 답하지 못할 수 있습니다. 오늘 실제로 통합하거나 다운로드할 수
있는가?
지금 HappyHorse 1.0을 이해하는 가장 좋은 방법은 두 칼럼으로 나눠 보는 것입니다.
영역
오늘 공개적으로 검증된 것
여전히 보고되었거나 추론된 것
리더보드 상태
2026년 4월 9일 기준 Artificial Analysis 의 네 가지 공개 비디오 슬라이스를 모두 선도한다
더 많은 투표가 들어오면 이 우위가 얼마나 안정적으로 유지될지
공개 가용성
공식 공개 weights 도, 퍼스트파티 공식 GitHub repo 도 없다
향후 open release 가 weights 와 inference code 를 포함할지
제품 아이덴티티
HappyHorses 공개 사이트는 이를 standalone 모델이 아니라 플랫폼 내 기능으로 다룬다
benchmark 모델명이 미래 standalone 릴리스와 1대1 대응하는지
아키텍처
퍼스트파티 기술 논문으로 확인된 내용이 없다
약 15B 파라미터, 통합 멀티모달 Transformer, DMD 스타일 distillation, 별도 audio module 없음이라는 주장
오디오 주장
오디오 포함 평가 슬라이스에 참여하고 여전히 강하다는 점은 리더보드에서 확인 가능하다
정확한 오디오 생성 pipeline 과 alignment 방식
Open-source 상태
공개 GitHub tracker 는 아직 공식 open-source 릴리스가 없다고 말한다
정확한 출시 시점, 라이선스, 패키징 형태
이 표가 이 글에서 가장 중요한 필터입니다.
이게 없으면 대화는 두 가지 잘못된 극단으로 무너집니다.
주장된 능력은 모두 이미 실제이며 출하 가능하다고 믿는 사람들
릴리스 스토리가 깔끔하지 않으니 전부 가짜일 것이라고 믿는 사람들
더 똑똑한 입장은 중간입니다.
benchmark 성능 신호는 주목할 만큼 충분히 진짜 같지만, release 와
정체성 신호는 강하게 신뢰하기에는 아직 너무 불완전하다 는 것입니다.
여기에 한 가지 nuance 가 더 있습니다. HappyHorse 는 오디오 없는
리더보드에서 가장 강해 보입니다. 오디오가 들어가면 우위는 훨씬 덜
결정적입니다. 실무적으로 보면, 현재 이 모델의 평판은 시각적 선호도
리더십 에 더 크게 의해 움직이고 있으며, 오디오 중심 production workflow 를
이미 지배한다고까지 말하기는 어렵습니다.
HappyHorse 1.0 이 더 주목받는 이유는, 보고된 능력 묶음이 출시 시점에 사실로
확인된다면 정말 인상적이기 때문입니다.
자주 나오는 주장은 다음과 같습니다.
원생의 joint audio-video generation
다국어 lip-sync
하나의 시스템 안에서 text-to-video 와 image-to-video 둘 다 지원
1080p 출력
느린 다단계 sampling 대신 빠른 distilled inference
코어 모델뿐 아니라 더 실전적인 production 구성 요소까지 포함하는 open
release 계획
설령 이 중 대부분만 맞아도 HappyHorse 1.0 이 중요한 이유는 단순합니다.
오늘날 open video models 가 여전히 메우지 못하는 정확한 간극을 겨냥하기
때문입니다.
그 간극은 단지 화질이 아닙니다. 다음의 조합입니다.
강한 비주얼
원생 사운드
강한 image-to-video 제어
실용적인 속도
크리에이터가 실제로 쓸 수 있는 릴리스 형식
현재의 많은 오픈 또는 open-adjacent 비디오 workflow 는 여전히 여러 단계를
이어 붙여야 합니다. 무음 영상을 만들고, 음성을 붙이고, 립싱크를 보정하고,
타이밍을 조정하고, 그 과정에서 일관성을 유지하려고 합니다. 만약 이 체인의
더 많은 부분을 한 번에 닫을 수 있다면, 그것은 단순한 리더보드 순위 상승이
아니라 실제 변화처럼 느껴질 것입니다.
문제는 공개 증거가 아직 충분하지 않다는 점입니다. 지금은 이런 능력 주장을
그럴듯하게 보고된 설계 주장 으로 보는 것이 가장 타당하며, 곧바로
production-ready 사실로 취급해서는 안 됩니다.
HappyHorse 1.0 은 고성능 AI 비디오 모델의 미스터리한 아이덴티티 로,
이미 공개 blind ranking 환경에서 강함을 입증했지만, 크리에이터가 이를
일반적인 오픈소스 모델이나 충분히 문서화된 상용 모델처럼 다룰 수 있게 해줄
검증된 릴리스 인프라는 아직 부족합니다.
그 전까지는 production dependency 가 아니라 watchlist model 로 다루는 것이
맞습니다.
지금 정말 필요한 것이, 정체 불명의 릴리스가 명확해질 때까지 기다리는 것이
아니라 frontier 비디오 워크플로를 바로 시험해 보는 것이라면,
Veo 4 가 더 안전한 경로입니다.
확인되지 않은 하나의 아이덴티티에 파이프라인 전체를 거는 대신, 여러 상위
비디오 생성 경로를 실제 작업 공간에서 평가할 수 있기 때문입니다.
네. 2026년 4월 9일 기준 Artificial Analysis 는 HappyHorse 1.0 을
text-to-video 와 image-to-video 전반에서, 오디오 포함/미포함 모두 1위로
표시합니다. 다만 Elo 수치는 시간이 지나며 더 많은 blind vote 가 들어오면
계속 변할 수 있습니다.