Le paysage de la génération vidéo par IA a connu une transformation spectaculaire début 2026. Deux modèles ont émergé comme leaders dans cet espace en évolution rapide : Veo 3.1 de Google, mis à jour en janvier avec des capacités 4K révolutionnaires, et Seedance 2.0 de ByteDance, lancé en février avec une architecture d'entrée multimodale innovante. Tous deux représentent la pointe de ce qui est possible en vidéo générée par IA, mais ils adoptent des approches fondamentalement différentes pour résoudre les mêmes défis créatifs.
Ce comparatif complet examine ces deux modèles phares sous tous les angles qui comptent pour les créateurs, les développeurs et les entreprises en 2026. Nous avons analysé les spécifications techniques vérifiées, les benchmarks de performance réels, les structures tarifaires et les cas d'utilisation pratiques pour vous fournir les informations nécessaires à une décision éclairée.
Flexibilité : Jusqu'à 12 fichiers de référence par génération
Vitesse : 30 % plus rapide que son prédécesseur
Résolution 2K native : Support natif 2048×1152
Expressions faciales et synchronisation labiale multilingue : Expressivité exceptionnelle
Le choix entre ces modèles ne consiste pas à savoir lequel est « meilleur » dans l'absolu, mais lequel s'aligne avec votre méthode de production, vos exigences créatives et vos objectifs.
Comprendre les capacités techniques de chaque modèle fournit la base pour un choix éclairé. Voici comment Veo 3.1 et Seedance 2.0 se comparent sur les spécifications critiques :
Veo 3.1 a fait les gros titres en janvier 2026 en devenant le premier modèle de génération vidéo par IA grand public à supporter une véritable sortie 4K. Cela représente un bond massif dans la fidélité visuelle, ouvrant des portes pour des applications professionnelles auparavant impossibles avec du contenu généré par IA.
La fonction de mise à l'échelle 4K, disponible via Google Flow, Gemini API et Vertex AI, produit une vidéo à 3840×2160 pixels — soit quatre fois la résolution de la sortie 1080p standard. Ce niveau de détail rend Veo 3.1 adapté aux usages haut de gamme, y compris les publicités télévisées, les panneaux d'affichage numériques, les pré-rolls de cinéma et le contenu YouTube premium où la qualité visuelle ne peut être compromise.
Au-delà du nombre brut de pixels, Veo 3.1 excelle dans ce que les professionnels de l'industrie appellent la « qualité visuelle de niveau cinéma ». Le modèle produit une sortie avec une science des couleurs professionnelle, un éclairage sophistiqué imitant la physique du monde réel, un flou de mouvement naturel et des textures de type film. Plusieurs comparaisons indépendantes ont noté que Veo 3.1 produit « le rendu le plus prêt pour la diffusion avec sa fréquence d'images standard cinéma et sa science des couleurs professionnelle » parmi les modèles vidéo IA actuels.
Seedance 2.0 adopte une approche différente avec une résolution native 2K à 2048×1152 pixels. Bien que cela n'égale pas la capacité 4K de Veo 3.1, le 2K représente une amélioration significative par rapport au 1080p standard et fournit une qualité plus que suffisante pour la plupart des applications numériques, y compris les réseaux sociaux, le contenu web et la production vidéo standard. Le modèle compense sa résolution maximale inférieure par un rendu des détails exceptionnel, particulièrement impressionnant dans les démonstrations de produits où les textures, logos et emballages doivent être reproduits avec précision.
Ce que Seedance 2.0 peut manquer en résolution absolue, il le compense dans d'autres dimensions de qualité visuelle. Le modèle se démarque clairement dans les expressions faciales et l'animation de personnages, avec un rendu qui dépasse le style robotique encore visible chez de nombreux modèles vidéo IA.
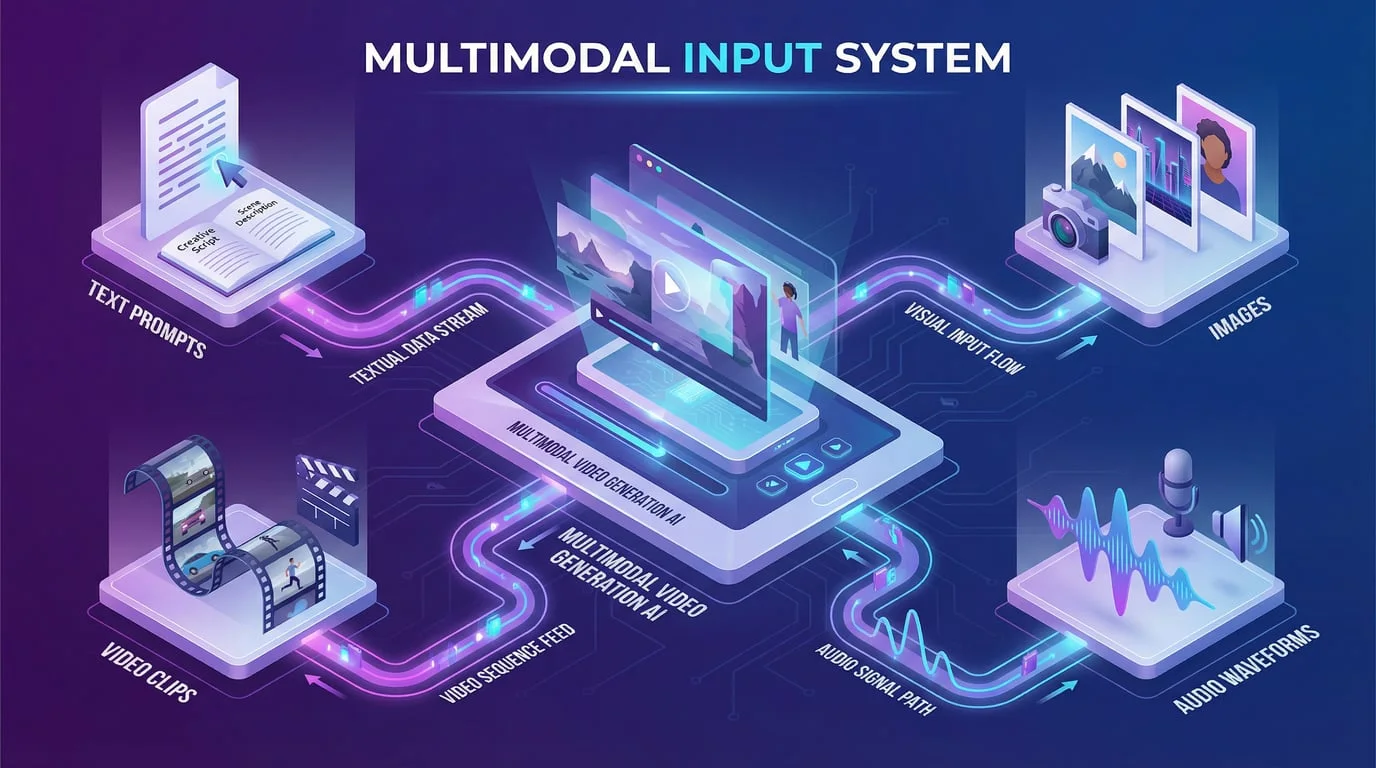
L'innovation la plus significative de Seedance 2.0 réside dans son architecture d'entrée multimodale — un changement fondamental dans la façon dont les créateurs interagissent avec les outils de génération vidéo par IA. Au lieu de s'appuyer uniquement sur des invites textuelles ou des images de référence uniques, Seedance 2.0 accepte quatre types d'entrée distincts simultanément : descriptions textuelles, jusqu'à neuf images, trois clips vidéo et trois fichiers audio, pour un total de 12 fichiers de référence par génération.
Cette approche multimodale transforme le processus de génération vidéo de « décris ce que tu veux » à « montre à l'IA ce que tu veux ». Le modèle utilise un système innovant de mention « @ » qui permet aux créateurs de spécifier exactement comment chaque actif téléchargé doit être utilisé. Vous pouvez référencer le visage d'un personnage spécifique d'une image, copier le mouvement de caméra d'un clip vidéo, correspondre au rythme d'une piste audio et guider l'esthétique globale avec une référence de style — le tout en une seule génération.
Les implications pratiques de cette architecture sont substantielles. Une équipe marketing créant une vidéo produit peut télécharger la photo du produit, une vidéo de référence montrant le mouvement de caméra souhaité, la musique de la marque et une description textuelle — et recevoir une vidéo cohérente intégrant tous ces éléments. Un créateur de contenu réalisant un clip musical peut fournir la photo de l'artiste, des images de référence de chorégraphie, la piste audio réelle et des descriptions de scènes pour générer un contenu synchronisé. Ce niveau de contrôle n'était tout simplement pas possible avec les modèles de génération précédente.
Veo 3.1 adopte une approche plus rationalisée avec sa fonctionnalité « Ingrédients vers Vidéo » (Ingredients to Video), acceptant jusqu'à quatre images de référence par génération. Bien que cela offre moins de flexibilité que le système à 12 fichiers de Seedance 2.0, cela offre un autre type de précision. Le modèle excelle à maintenir l'identité du personnage à travers les changements de scène — résolvant le problème persistant de la « dérive d'identité » (identity drift) où l'apparence d'un personnage change subtilement entre les plans. Le système garantit que le visage, les vêtements et les caractéristiques physiques d'un personnage restent identiques dans différentes scènes, ce qui est critique pour le contenu narratif.
Veo 3.1 offre également un outil d'interpolation unique « Images vers Vidéo » (Frames to Video) permettant aux créateurs de fournir une image de début et de fin, l'IA générant une transition cinématographique respectant l'éclairage et la physique des deux cadres. Ce mode de contrôle première et dernière image reste exclusif à Veo 3.1 parmi les modèles vidéo IA majeurs.
L'audio représente l'un des différenciateurs les plus significatifs entre les modèles vidéo IA modernes et leurs prédécesseurs. Tant Veo 3.1 que Seedance 2.0 génèrent de l'audio nativement aux côtés de la vidéo, mais ils abordent ce défi sous des angles différents.
La génération audio intégrée de Veo 3.1 crée des bandes sonores synchronisées incluant dialogues, effets sonores et musique de fond en une seule passe à travers l'architecture du modèle. Cette génération audiovisuelle unifiée assure un alignement temporel parfait entre ce que les spectateurs voient et ce qu'ils entendent. Le système comprend suffisamment le contexte pour générer des sons appropriés — des pas correspondant à la démarche d'un personnage, un bruit ambiant adapté à l'environnement, et une musique complétant l'ambiance visuelle. Pour les développeurs, Veo 3.1 reste particulièrement fort grâce à son API Google officielle et à sa génération audio native.
L'avantage pratique de l'approche de Veo 3.1 devient évident dans les flux de production. Pour les créateurs produisant du contenu où la cohérence audiovisuelle compte — publicités, contenu social avec voix off, ou courts métrages narratifs — la génération audio native peut économiser des heures de travail de post-production par projet. L'audio n'est pas un ajout postérieur ; il est généré avec une pleine conscience du contenu visuel, résultant en une synchronisation plus serrée que ce que la plupart des flux de post-production peuvent atteindre.
Seedance 2.0 adopte une approche différente via son système audio basé sur référence. Plutôt que de générer l'audio à partir de zéro basé sur la compréhension de la scène, le modèle peut accepter des fichiers audio comme entrée et synchroniser la génération vidéo pour correspondre au rythme, à l'humeur et au timing de l'audio. C'est particulièrement puissant pour les clips musicaux, le contenu de danse ou tout scénario où la piste audio est prédéterminée et la vidéo doit correspondre précisément.
La capacité de synchronisation sur le rythme du modèle analyse l'audio téléchargé et génère une vidéo avec des mouvements, des coupes et des éléments visuels qui s'alignent sur la musique. Combiné avec sa fonctionnalité de synchronisation labiale multilingue — qui comprend les formes de bouche spécifiques à la langue (visèmes) et génère des mouvements de lèvres précis pour le chinois, l'anglais et l'espagnol — Seedance 2.0 excelle dans la création de vidéos d'humains numériques et de contenu centré sur les personnages où la synchronisation audiovisuelle précise est critique.
La crédibilité de la vidéo générée par IA dépend largement de la façon dont le modèle comprend et simule la physique du monde réel. Les objets doivent bouger avec un poids et une inertie convaincants, les tissus doivent tomber naturellement, les fluides doivent se comporter comme des fluides, et les interactions entre objets doivent sembler plausibles.
Les deux modèles ont fait des progrès significatifs dans le réalisme physique, mais via des approches techniques différentes. Seedance 2.0 intègre des objectifs d'entraînement améliorés conscients de la physique qui pénalisent les mouvements physiquement invraisemblables pendant le processus de génération. En pratique, cela rend la gravité, la retombée des tissus, le comportement des fluides et les interactions d'objets nettement plus crédibles.
L'amélioration est particulièrement notable dans les scénarios impliquant des mouvements complexes — les vêtements d'un danseur flottant naturellement, l'eau éclaboussant avec une physique réaliste, ou des objets interagissant avec un poids et une inertie appropriés. Pour les développeurs et créateurs, cela compte car le réalisme du mouvement est le facteur unique le plus important déterminant si une vidéo générée par IA franchit le seuil de « démo intéressante » à « actif prêt pour la production ».
Veo 3.1 aborde le réalisme physique via son pipeline de rendu de niveau cinéma, qui met l'accent sur le flou de mouvement naturel, les interactions d'éclairage réalistes et une compréhension sophistiquée de la façon dont les caméras capturent le mouvement. La fréquence d'images standard cinéma de 24fps du modèle contribue à une qualité de type film qui semble plus naturelle aux spectateurs habitués au contenu vidéo professionnel. En pratique, Veo 3.1 excelle dans l'éclairage cinématographique, les textures, le flou de mouvement et le réalisme global de type film.
Les benchmarks de l'industrie identifient constamment Sora 2 d'OpenAI comme le leader en pure simulation physique, mais tant Veo 3.1 que Seedance 2.0 ont considérablement réduit l'écart. Pour la plupart des applications pratiques — contenu marketing, vidéos de réseaux sociaux, démonstrations de produits — les deux modèles offrent une qualité physique répondant aux normes professionnelles.
La durée de la vidéo représente une contrainte pratique critique dans la génération vidéo par IA. Des durées plus longues permettent un storytelling plus complexe et réduisent le besoin d'assembler plusieurs clips, mais elles augmentent également le défi technique de maintenir la cohérence à travers les images.
Seedance 2.0 offre un avantage significatif ici avec le support jusqu'à 20 secondes par génération. Cette durée étendue fournit substantiellement plus d'espace pour le développement narratif, les actions complexes et la progression de scène sans nécessiter plusieurs générations. Le modèle maintient la cohérence sur cette période plus longue, traitant l'un des problèmes persistants de la vidéo IA où l'apparence du personnage, les détails des objets ou les éléments de scène dérivaient ou changeaient de manière inattendue au milieu du clip.
Veo 3.1 plafonne la génération à 8 secondes par clip, ce qui oblige les créateurs travaillant sur du contenu plus long à générer plusieurs clips et à les assembler. Cependant, le modèle compense cette limitation par une cohérence exceptionnelle au sein de ces 8 secondes et des outils conçus spécifiquement pour les montages multi-clips. La cohérence améliorée de la fonctionnalité « Ingrédients vers Vidéo » garantit que les personnages, arrière-plans et objets conservent leur apparence à travers des générations séparées, rendant le processus d'assemblage plus fluide.
Pour les créateurs concentrés sur le contenu court — Instagram Reels, TikTok, YouTube Shorts — la limite de 8 secondes de Veo 3.1 est moins contraignante. Le support natif de la vidéo verticale 9:16 du modèle, sorti dans la mise à jour de janvier 2026, cible spécifiquement la création de vidéo courte orientée mobile. Cette génération verticale native élimine le besoin de recadrer la vidéo horizontale, préservant le contrôle de la composition et la qualité de l'image.
Comprendre la structure des coûts de la génération vidéo par IA est essentiel pour évaluer quel modèle correspond à votre budget et à votre volume de production. Les deux modèles offrent plusieurs niveaux d'accès avec une tarification significativement différente.
La tarification de Veo 3.1 varie considérablement selon la plateforme d'accès et les paramètres de qualité. Via les abonnements Google AI Pro (19,99 $/mois), le coût effectif est d'environ 0,16 $ par seconde basé sur l'allocation mensuelle de crédits. La tarification API via Vertex AI et Gemini API varie de 0,10-0,15 $ par seconde pour la variante rapide à 0,50-0,75 $ par seconde pour le point d'accès standard avec qualité complète.
La variante rapide atteint une vitesse de génération doublée grâce à une optimisation algorithmique avec seulement 1-8 % de compromis sur la qualité, ce qui en fait un excellent choix pour les itérations de brouillon et le contenu social à haut volume. La variante standard livre une qualité maximale pour les rendus finaux de production. Ce système à deux niveaux permet aux créateurs d'optimiser les coûts en utilisant le mode rapide pour l'exploration et les tests créatifs, puis en basculant vers le mode standard pour les livrables finaux.
La tarification de Seedance 2.0 reste officiellement non annoncée en date de février 2026, le modèle étant toujours en accès bêta limité principalement via la plateforme Jimeng AI de ByteDance. Les estimations actuelles tournent autour de 0,60 $ par vidéo de 10 secondes en résolution 2K, ce qui le placerait dans le milieu de gamme si ce niveau se confirme. Le modèle est actuellement accessible gratuitement via la plateforme Jimeng AI pendant la période bêta, bien que l'accès API de production n'ait pas encore été officiellement lancé.
Pour les développeurs et les entreprises planifiant des déploiements en production, l'écosystème API mature de Veo 3.1 via Google Cloud offre des avantages significatifs en fiabilité, documentation et support d'intégration. La disponibilité de l'API de Seedance 2.0 reste limitée, bien que des plateformes d'agrégation d'API tiers aient commencé à offrir un accès non officiel.
Le choix entre Veo 3.1 et Seedance 2.0 revient souvent aux exigences spécifiques du cas d'utilisation. Voici comment chaque modèle performe dans des scénarios courants :
Pour la production commerciale haut de gamme et le contenu de diffusion :
Veo 3.1 est le choix clair. La capacité de résolution 4K, la science des couleurs de niveau cinéma et l'éclairage professionnel en font le seul modèle IA actuel adapté aux publicités télévisées, pré-rolls de cinéma et publicité numérique premium où la qualité visuelle ne peut être compromise. La sortie prête pour la diffusion nécessite un post-traitement minimal pour répondre aux normes professionnelles.
Pour le contenu des réseaux sociaux et le marketing numérique :
Les deux modèles excellent ici, mais avec des forces différentes. Le support vidéo vertical natif de Veo 3.1 et le mode de génération rapide le rendent idéal pour la production de réseaux sociaux à haut volume ciblant Instagram, TikTok et YouTube Shorts. Le système d'entrée multimodale de Seedance 2.0 offre plus de contrôle créatif pour le contenu spécifique à la marque où le maintien de l'identité visuelle à travers plusieurs actifs est critique.
Pour les clips musicaux et le contenu synchronisé au rythme :
Seedance 2.0 domine cette catégorie. La capacité de télécharger des pistes audio et de faire générer par le modèle une vidéo synchronisée au rythme, combinée aux capacités de synchronisation labiale multilingue, le rend spécialement conçu pour la création de clips musicaux, le contenu de danse et tout scénario où l'audio conduit le rythme visuel.
Pour les démonstrations de produits et l'e-commerce :
Le rendu des détails amélioré de Seedance 2.0 excelle à reproduire avec précision les textures de produits, logos et emballages. L'entrée multimodale permet aux marchands de télécharger des photos de produits, de démontrer les mouvements de caméra souhaités via des vidéos de référence, et de générer rapidement du contenu de vitrine professionnel. La précision et le rythme contrôlé de Veo 3.1 fonctionnent également bien pour les vidéos de produits mettant l'accent sur des visuels propres et une présentation professionnelle.
Pour le storytelling narratif et le contenu axé sur les personnages :
La durée de 20 secondes et la qualité exceptionnelle des expressions faciales de Seedance 2.0 le rendent bien adapté aux vidéos narratives avec résonance émotionnelle. La capacité du modèle à maintenir la cohérence du personnage sur des clips plus longs réduit les défis techniques du storytelling multi-scènes. La cohérence de l'identité du personnage de Veo 3.1 à travers des générations séparées fonctionne également bien pour le contenu narratif, bien que la limite de 8 secondes nécessite plus de planification pour le séquençage des scènes.
Pour l'intégration développeur et les flux d'automatisation :
L'API officielle Google de Veo 3.1, sa documentation complète et sa fiabilité de niveau entreprise en font le choix supérieur pour les développeurs intégrant la génération vidéo dans des applications, produits ou processus automatisés. La maturité de l'API et l'intégration Google Cloud fournissent la stabilité requise pour les déploiements en production.
Au-delà des spécifications techniques, le comportement en production compte tout autant.
Veo 3.1 se distingue par sa qualité visuelle et son ressenti cinématographique. La fonction de mise à l'échelle 4K a ouvert de nouveaux cas d'utilisation pour la vidéo générée par IA dans des contextes professionnels auparavant interdits en raison des contraintes de résolution. La sortie paraît professionnelle et nécessite souvent moins de post-traitement que les modèles concurrents. La génération audio native est globalement pertinente sur le plan contextuel, même si la qualité audio varie encore selon la complexité de la scène.
Seedance 2.0 a généré un enthousiasme significatif pour son système de contrôle multimodal. Le modèle marque un vrai passage de la démo impressionnante à l'outil réellement utile. Les expressions faciales sont particulièrement solides, et les animations de personnages paraissent plus naturelles et moins robotiques que chez beaucoup de concurrents.
La vitesse de génération représente une considération pratique dans les flux de production. L'amélioration de 30 % de la vitesse de Seedance 2.0 par rapport à son prédécesseur se traduit par des cycles d'itération plus rapides, ce qui compte significativement lors de l'exploration de directions créatives ou de la génération de hauts volumes de contenu. Le mode Rapide de Veo 3.1 offre des avantages de vitesse similaires, bien qu'avec le compromis de qualité de 1-8 % noté.
Les deux modèles présentent encore des artefacts et erreurs occasionnels communs à la génération vidéo par IA — violations de la physique, incohérences temporelles ou éléments visuels inattendus. Cependant, la fréquence et la sévérité de ces problèmes ont considérablement diminué par rapport aux modèles de génération précédente. Pour la plupart des cas d'utilisation, le taux d'erreur est tombé sous le seuil empêchant l'utilisation en production.
Bien que cette comparaison se concentre sur Veo 3.1 et Seedance 2.0, comprendre où ils se situent dans le paysage concurrentiel plus large fournit un contexte précieux. Sora 2 d'OpenAI reste la référence pour le réalisme physique pur, en faisant le choix préféré lorsque les objets doivent interagir avec une précision physique convaincante. Kling 3.0 de Kuaishou offre du 4K natif à 60fps avec une excellente qualité de mouvement et un niveau gratuit, le rendant attrayant pour les créateurs soucieux des coûts.
De nombreuses équipes de production professionnelles utilisent plusieurs modèles stratégiquement — Seedance 2.0 pour le travail basé sur des modèles et le contenu nécessitant un contrôle multimodal, Veo 3.1 pour les livrables finaux de haute qualité nécessitant une résolution 4K, et d'autres modèles pour des forces spécifiques. Le paysage concurrentiel a mûri au point où le choix du modèle est devenu une décision stratégique de production plutôt qu'une recherche d'une option « meilleure » unique.
Comprendre les capacités de Veo 3.1 et Seedance 2.0 n'est précieux que si vous pouvez réellement y accéder et les utiliser efficacement. Veo4.im offre un accès pratique à plusieurs modèles de génération vidéo et d'image de pointe via une plateforme unifiée, éliminant la complexité de gérer plusieurs intégrations API et points d'accès.
La plateforme permet aux créateurs, développeurs et entreprises d'utiliser des modèles IA de pointe sans le surcoût technique des intégrations API directes. Cette approche d'accès unifié signifie que vous pouvez tester différents modèles pour des cas d'utilisation spécifiques, basculer entre eux selon les exigences du projet et optimiser votre organisation de production sans être enfermé dans l'écosystème d'un seul fournisseur.
Pour les équipes évaluant quel modèle répond le mieux à leurs besoins de production, avoir accès à plusieurs options via une seule interface réduit considérablement la friction des tests comparatifs. Vous pouvez générer la même invite sur différents modèles, comparer les résultats côte à côte et prendre des décisions éclairées basées sur la sortie réelle plutôt que sur des spécifications théoriques.
L'évolution rapide de la génération vidéo par IA début 2026 suggère que nous sommes encore aux premiers stades de la courbe de développement de cette technologie. L'atteinte de la résolution 4K dans Veo 3.1 et l'architecture multimodale de Seedance 2.0 représentent des jalons significatifs, mais ils pointent également vers des capacités futures qui transformeront davantage la production vidéo.
Les développements attendus à court terme incluent des durées de génération plus longues, une simulation physique améliorée, une meilleure cohérence temporelle sur des clips étendus, une génération audio plus sophistiquée et des systèmes de contrôle améliorés donnant aux créateurs une influence encore plus précise sur la sortie. La pression concurrentielle entre Google, ByteDance, OpenAI et d'autres acteurs garantit une itération rapide et une amélioration constante.
Pour les créateurs et les entreprises, cela signifie qu'investir dans la compréhension de ces outils maintenant — apprendre leurs forces, limitations et cas d'utilisation optimaux — offre un avantage concurrentiel à mesure que la technologie continue de mûrir. Les méthodes de production et approches créatives développées aujourd'hui s'adapteront à mesure que les modèles sous-jacents s'améliorent.
Veo 3.1 et Seedance 2.0 représentent deux philosophies différentes dans la génération vidéo par IA, toutes deux exécutées à un haut niveau de sophistication technique. Veo 3.1 priorise une qualité visuelle maximale, un poli cinématographique et une sortie de niveau professionnel adaptée aux cas d'utilisation les plus exigeants. Seedance 2.0 met l'accent sur le contrôle créatif, la flexibilité et la capacité de fusionner plusieurs sources de référence dans une génération unifiée.
Aucun modèle n'est universellement « meilleur » — ils excellent dans différents scénarios et servent différents besoins créatifs. Veo 3.1 est l'outil pour le créateur qui a besoin de résultats de qualité diffusion et est prêt à travailler dans ses contraintes. Seedance 2.0 est le choix pour le créateur qui valorise le contrôle, la flexibilité et la capacité de diriger l'IA comme un assistant de production plutôt que de simplement lui donner des invites.
La maturité des deux modèles signale que la génération vidéo par IA a franchi le seuil critique de technologie expérimentale à outil prêt pour la production. La question n'est plus de savoir si l'IA peut générer une vidéo utilisable, mais quel modèle convient le mieux à votre méthode de production, vos exigences créatives et vos objectifs.
Pour un accès pratique à ces modèles vidéo IA de pointe et d'autres, Veo4.im fournit une plateforme unifiée qui simplifie la complexité de travailler avec plusieurs modèles frontières, vous permettant de vous concentrer sur la créativité plutôt que sur l'intégration technique.
Veo 3.1 vs Seedance 2 : Le comparatif ultime de la génération vidéo par IA en 2026
Résumé : Quel modèle l'emporte ?
Spécifications techniques : Comparaison côte à côte
Résolution et qualité visuelle : L'avantage 4K
La révolution multimodale : La caractéristique déterminante de Seedance 2.0
Génération audio : Synchronisation native vs Contrôle basé sur référence
Réalisme physique et qualité du mouvement
Durée et cohérence temporelle
Tarification et accessibilité
Analyse des cas d'utilisation : Quel modèle pour quel scénario ?