If you search for what is happyhorse 1.0, you are usually trying to solve a
very specific confusion.
You have seen the name jump to the top of the Artificial Analysis video
leaderboards. You have seen people call it a coming-soon open model, a mystery
Asia-based release, a stealth benchmark submission, or a wrapper product. You
have also seen capability claims that sound unusually ambitious for an unreleased
video model: native audio, multilingual lip-sync, strong text-to-video, strong
image-to-video, and surprisingly fast generation.
The practical answer is more restrained than the hype.
As of April 9, 2026, HappyHorse 1.0 is best understood as a mystery video
model identity attached to elite benchmark results, but not yet backed by a
public official repository, public weights, or a first-party technical report.
That is why it is getting so much attention and why the discussion around it
feels unusually chaotic.
This guide does four things:
explains what HappyHorse 1.0 is in the most defensible way possible
shows why the leaderboard results matter
separates verified facts from reported claims
gives you a usable framework for deciding whether to watch it, wait for it, or
ignore the hype for now
HappyHorse 1.0 is not easy to classify because the public signals point in two
different directions at the same time.
On one side, the model name currently sits at the top of the public Artificial
Analysis leaderboards for both text-to-video and image-to-video, with and
without audio. That gives it immediate credibility as a serious frontier video
entry.
On the other side, the public release story is still weak:
there is no official public GitHub repository
there are no public downloadable weights
there is no public official technical paper
the main public HappyHorses site describes HappyHorse as a capability inside a
SaaS platform, not as a standalone downloadable model offering
That leads to the most useful working definition right now:
HappyHorse 1.0 is a benchmark-leading video model identity with strong public
performance signals, but it is still not a fully verified public open-weights
release.
The reason is simple: the leaderboard positions are hard to ignore.
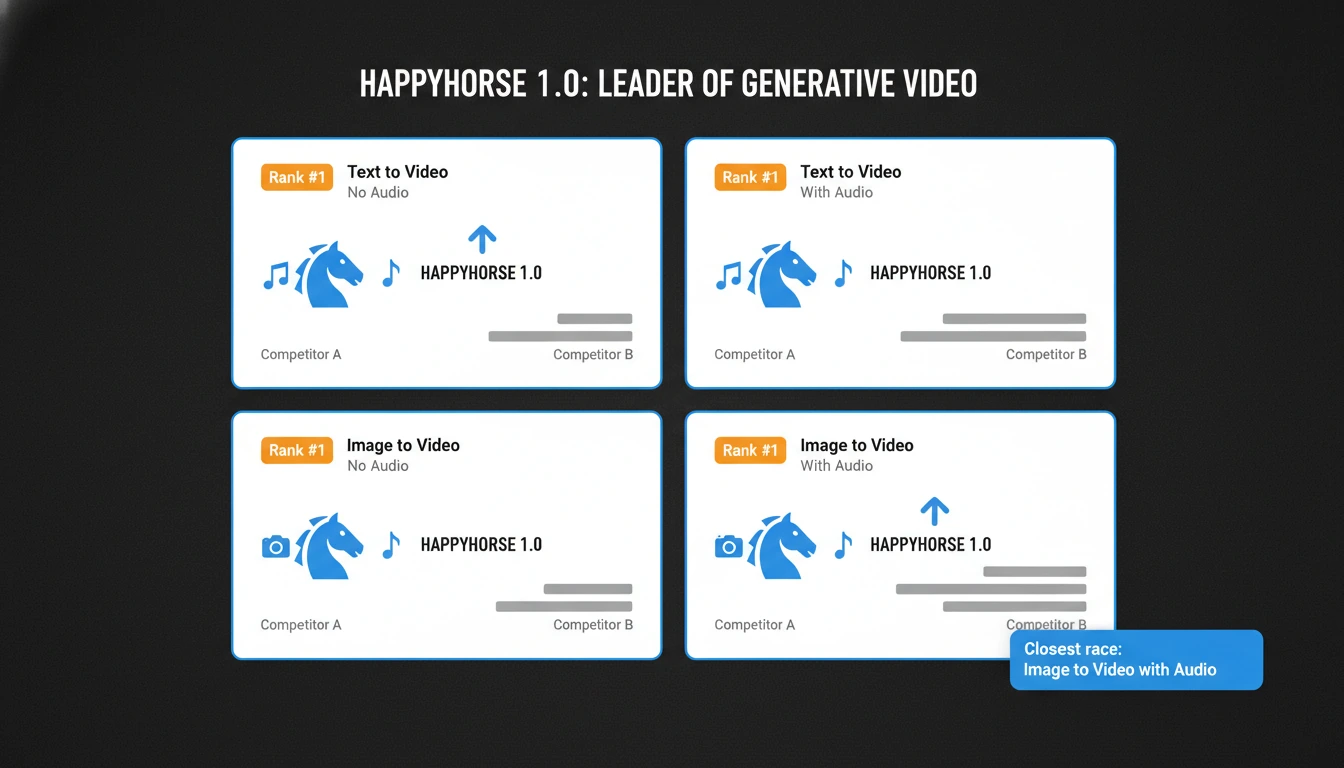
As of April 9, 2026, Artificial Analysis lists HappyHorse 1.0 at number one in
all four main public slices of its video leaderboard system:
Category
HappyHorse 1.0 status
Elo score
Why it matters
Text-to-video, no audio
#1
1383
This is the clearest signal that people prefer its raw visual output in blind voting
Text-to-video, with audio
#1
1229
It leads the current public field even when audio is included
Image-to-video, no audio
#1
1413
This is its strongest public lead and suggests unusually strong visual control or preference
Image-to-video, with audio
#1
1165
It still leads, but only by a hair, which matters for perspective
Artificial Analysis also surfaces three extra details that matter and that many
quick writeups skip:
HappyHorse-1.0 is listed among the models added to the leaderboard in the
last month
its public availability on the leaderboard is still marked as Coming soon
rather than a normal live API offer
the no-audio slices already have non-trivial sample counts behind them, which
makes the ranking harder to dismiss as a tiny-sample fluke
The current snapshot is especially useful on the sample-count point. In the
public no-audio tables, Artificial Analysis shows 3,895 samples behind
HappyHorse in text-to-video and 11,153 samples behind HappyHorse in
image-to-video. That does not make the ranking permanent, but it does mean the
model is not floating at the top on a near-empty vote pool.
This is not a normal kind of hype cycle.
Usually, mystery models trend because of a flashy demo or a rumor. HappyHorse
1.0 is trending because it has already earned top placement in a public blind
arena. Artificial Analysis does not rank models by loud marketing pages. It
ranks them with Elo scores derived from blind comparisons, where people compare
two outputs from the same prompt or the same source image without seeing the
model names first.
That system does not make the model identity trustworthy by itself, but it does
make the output performance signal much harder to dismiss.
This is the core tension behind the entire keyword.
The benchmark story says:
this model is already beating or matching the strongest commercial entries
it competes well in both text-to-video and image-to-video
it stays competitive even when audio is part of the evaluation
The release story says:
you still cannot treat it like Wan 2.2, LTX-2, or another verified open-weights
model
you cannot download it
you cannot audit a real official repo
you cannot inspect official licensing terms
you cannot verify the architecture through a first-party paper
That gap explains why the comments feel split between excitement and suspicion.
A model that ranks this high usually arrives with a cleaner identity. You expect
one of two things:
a commercial product with documented access and pricing
an open release with weights, code, and a paper
HappyHorse 1.0 currently sits in an unusual middle state. The quality signal is
public. The identity and distribution signal is still blurry.
The Coming soon label on Artificial Analysis sharpens that point. It means the
story is not only about quality. It is also about missing access maturity.
A model can be first in blind preference and still fail the most basic builder
question: can I actually integrate or download it today?
One of the most important facts in this story is also one of the most
overlooked.
The happyhorses.io site does not frame HappyHorse as a public standalone
open-source package you can take and run yourself. It frames it as a video
generation capability inside the HappyHorses platform.
HappyHorse is available as part of a SaaS workflow
it is not currently offered as a standalone model product
it is not described there as a downloadable package
the platform explicitly says it does not claim ownership of the underlying AI
model technologies
That matters because it changes the question from:
Where do I download HappyHorse 1.0?
to:
Am I looking at a benchmark-winning model identity, a platform wrapper label, or an internal capability that is being presented through a SaaS product first?
This is exactly where many quick blog posts go wrong. They treat the benchmark
name and the product label as if they already map cleanly to a standard public
model release. They do not.
The best way to read HappyHorse 1.0 right now is with a two-column mental model:
Area
What is verified in public today
What is still only reported or inferred
Leaderboard status
It leads all four public Artificial Analysis video slices as of April 9, 2026
How stable that lead will remain as more votes come in
Public availability
No official public weights or first-party official GitHub repo are available
A future open release scope that includes weights and inference code
Product identity
The public HappyHorses site treats it as an in-platform capability, not a standalone model offering
Whether the benchmark model name maps one-to-one to a future standalone release
Architecture
Nothing is confirmed by a first-party technical paper
Around 15B parameters, unified multimodal Transformer, DMD-style distillation, and no separate audio module
Audio claims
The leaderboards show it participates in audio-enabled evaluation slices and still performs strongly
The exact audio-generation pipeline and how it achieves alignment
Open-source status
The public GitHub tracker says no official open-source release has happened yet
The exact release timing, license, and packaging format
This table is the article's most important filter.
Without it, the conversation collapses into two bad extremes:
people who assume every claimed capability is already real and shippable
people who assume the whole thing must be fake because the release story is not
clean yet
The smarter position is in the middle:
the benchmark performance signal looks real enough to deserve attention, but
the release and identity signal is still too incomplete for heavy trust.
One more nuance belongs here. HappyHorse looks strongest in the no-audio
leaderboards. The edge is much less decisive once audio becomes part of the
comparison. In practice, that means the model's current public reputation is
being driven more by visual preference leadership than by a clean public case
that it already dominates audio-first production workflows.
HappyHorse 1.0 is getting extra attention because the reported capability stack
would be genuinely impressive if it proves true at release.
The claims that show up most often include:
native joint audio-video generation
multilingual lip-sync
both text-to-video and image-to-video in one system
1080p output
fast distilled inference rather than slow long-step sampling
open release plans that would include the core model plus more production
pieces
If even most of that turns out to be accurate, HappyHorse 1.0 would matter for a
simple reason: it would aim at the exact gap that open video models still
struggle with today.
That gap is not only visual quality. It is the combination of:
strong visuals
native sound
strong image-to-video control
practical speed
a release format that creators can actually use
Most current open or open-adjacent video workflows still require stitching
together multiple steps. You generate silent video, then you add voice or sound,
then you repair lip-sync, then you adjust timing, then you try to keep
consistency intact. A model that genuinely closes more of that chain in one pass
would feel like a real shift, not just another incremental leaderboard entry.
The problem is that the public proof is still incomplete. Right now, those
capability claims are best treated as plausible reported design claims, not
as production-ready facts.
This group wants a local or semi-local breakthrough model. They are attracted by
the possibility that HappyHorse 1.0 could become:
a new open-video benchmark leader
a native-audio alternative to more fragmented pipelines
a serious upgrade over the open model field available today
The excitement here is easy to understand. Open video still feels behind the
best closed systems in some important ways, especially when audio and polished
motion quality matter.
This is where many readers need the clearest reality check.
HappyHorse 1.0 may already look stronger than the current open field in public
arena preference, but that does not put it in the same practical category as
the open models you can actually download and run now.
Model path
Public benchmark position
Downloadable today
Native audio story
Practical reality
HappyHorse 1.0
Strongest public overall signal right now
No
Claimed and partially implied by audio-enabled leaderboard performance
Great to watch, risky to depend on
LTX-2 Pro / LTX-2.3
Top current open-weights line on Artificial Analysis
Yes
More limited than the reported HappyHorse story
Real open workflow today
Wan 2.2 A14B
Strong open-weights reference point
Yes
No equivalent public native-audio breakthrough story
Good for real testing now
HunyuanVideo line
Public and inspectable
Yes
More traditional multi-step workflow expectations
Useful, but not a mystery leap
That is why the phrase best open video model is not enough on its own.
There are really two separate questions:
Which model looks strongest in blind preference right now?
Which model can I actually adopt in a serious workflow today?
HappyHorse 1.0 may have the strongest answer to the first question. It does not
yet have the strongest answer to the second.
There is also a third question that matters more than many comparison posts
admit:
Which model is both strong and publicly accessible with stable builder
interfaces?
That is where the practical leaderboard starts to change. If you filter for
models that already have real access paths, documented APIs, or verified
open-weights releases, the field looks very different from the pure Elo order.
HappyHorse 1.0 is a mystery high-performing AI video model identity that has
already proven itself in public blind ranking environments, but still lacks the
kind of verified release infrastructure that would let creators treat it as a
normal open-source or fully documented commercial model.
That definition is less exciting than the hype, but it is much more useful.
It tells you three things at once:
the model is worth paying attention to
the current public claims are not enough for blind trust
your evaluation should focus on release maturity, not only benchmark glory
That does not mean you should dismiss it. It means you should evaluate it with
the right threshold.
Build around HappyHorse 1.0 only after these signals become public:
an official first-party repo
real public weights or stable API access
a license you can evaluate
a technical paper or at least a formal technical note
repeatable examples beyond arena preference alone
Until then, the right move is to treat it as a watchlist model, not a production
dependency.
If your real need is to test frontier video workflows right now rather than wait
for a mystery release to clarify itself, Veo 4
is the safer path because it gives you a practical workspace for evaluating
multiple top video-generation routes without betting your pipeline on one
unconfirmed identity.
No. As of April 9, 2026, there is no official public weights release, no
official first-party GitHub repo, and no first-party technical paper that turns
it into a normal verified open-source release.
Yes. As of April 9, 2026, Artificial Analysis shows HappyHorse 1.0 at number one
across text-to-video and image-to-video, with and without audio. The exact Elo
numbers can still move over time as more blind votes arrive.
Not publicly. The main public HappyHorses site frames HappyHorse as a capability
inside the platform and explicitly says it is not offered as a standalone model
or downloadable package.
Not yet. Those claims are widely repeated, and some of them may eventually prove
true, but there is still no first-party public technical release that confirms
them in a way serious builders should treat as final.
Because public blind preference data is still meaningful. A model does not need a
clean press rollout to produce clips people consistently prefer. The quality
signal can be real even while the product identity stays muddy.