The AI video generation landscape has undergone a dramatic transformation in early 2026. Two models have emerged as frontrunners in this rapidly evolving space: Google's Veo 3.1, updated in January with groundbreaking 4K capabilities, and ByteDance's Seedance 2.0, launched in February with revolutionary multimodal input architecture. Both represent the cutting edge of what's possible in AI-generated video, yet they take fundamentally different approaches to solving the same creative challenges.
This comparison breaks down these two leading models across the dimensions that matter most to creators, developers, and businesses in 2026. It covers technical specifications, real-world performance, pricing structures, and practical use cases so you can make a clear decision.
Creative control through multimodal input (text + images + video + audio)
Flexibility with up to 12 reference files per generation
Speed (30% faster than its predecessor)
Native 2K resolution (2048×1152)
Facial expression quality and multi-language lip-sync
The choice between these models isn't about which is "better" in absolute terms—it's about which aligns with your specific workflow, creative requirements, and production goals.
Understanding the technical capabilities of each model provides the foundation for making an informed choice. Here's how Veo 3.1 and Seedance 2.0 compare across critical specifications:
Veo 3.1 made headlines in January 2026 by becoming the first mainstream AI video generation model to support true 4K output. This represents a massive leap in visual fidelity that opens doors for professional applications previously impossible with AI-generated content.
The 4K upscaling feature, available through Google Flow, Gemini API, and Vertex AI, produces video at 3840×2160 pixels—four times the resolution of standard 1080p output. This level of detail makes Veo 3.1 suitable for high-end use cases including television commercials, digital billboards, cinema pre-rolls, and premium YouTube content where visual quality cannot be compromised.
Beyond raw pixel count, Veo 3.1 delivers cinema-grade visual quality. The model produces output with professional color science, sophisticated lighting that mimics real-world physics, natural motion blur, and film-like textures. Across head-to-head comparisons, it stands out as some of the most broadcast-ready output among current AI video models.
Seedance 2.0 takes a different approach with native 2K resolution at 2048×1152 pixels. While this doesn't match Veo 3.1's 4K capability, 2K represents a significant improvement over standard 1080p and provides more than adequate quality for most digital applications including social media, web content, and standard video production. The model compensates for its lower maximum resolution with exceptional detail rendering, particularly impressive in product showcases where textures, logos, and packaging need to be accurately reproduced.
What Seedance 2.0 may lack in absolute resolution, it makes up for in other visual quality dimensions. The model stands out in facial expressions and character animation, moving beyond the robotic acting style that still affects many AI video models.
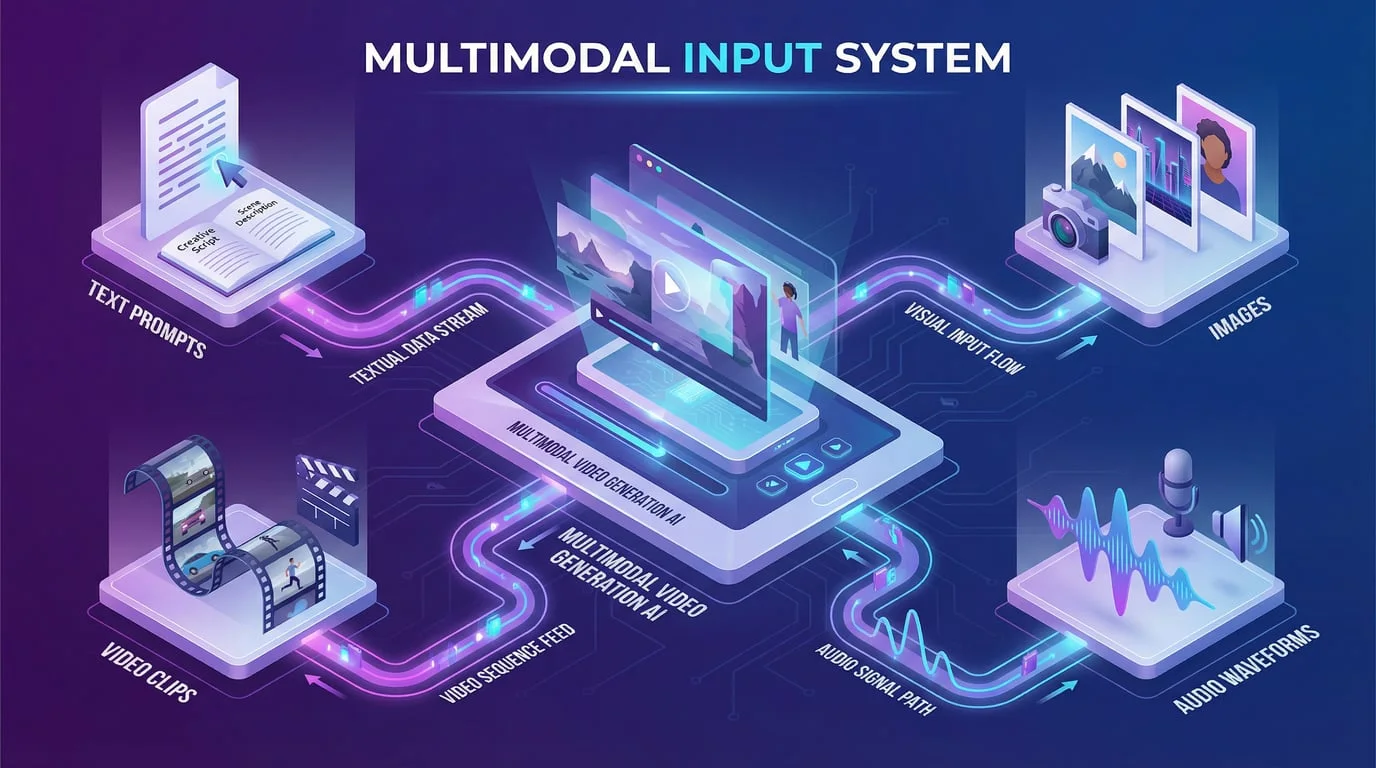
Seedance 2.0's most significant innovation lies in its multimodal input architecture—a fundamental shift in how creators interact with AI video generation tools. Rather than relying solely on text prompts or single reference images, Seedance 2.0 accepts four distinct input types simultaneously: text descriptions, up to nine images, three video clips, and three audio files, for a total of 12 reference files per generation.
This multimodal approach transforms the video generation process from "describe what you want" to "show the AI what you want." The model uses an innovative @ mention system that allows creators to specify exactly how each uploaded asset should be used. You can reference a specific character's face from one image, copy camera movement from a video clip, match the rhythm of an audio track, and guide the overall aesthetic with a style reference—all in a single generation.
The practical implications of this architecture are substantial. A marketing team creating a product video can upload the product photo, a reference video showing desired camera movement, brand music, and a text description—and receive a cohesive video that incorporates all these elements. A content creator making a music video can provide the artist's photo, choreography reference footage, the actual audio track, and scene descriptions to generate synchronized content. This level of control was simply not possible with previous generation models.
Veo 3.1 takes a more streamlined approach with its "Ingredients to Video" feature, accepting up to four reference images per generation. While this provides less flexibility than Seedance 2.0's 12-file system, it offers a different kind of precision. The model excels at maintaining character identity across scene changes—solving the persistent "identity drift" problem where a character's appearance would subtly change between shots. The system ensures that a character's face, clothing, and physical characteristics remain identical across different scenes, which is critical for narrative content.
Veo 3.1 also offers a unique "Frames to Video" interpolation tool that allows creators to provide a starting and ending image, with the AI generating a cinematic transition that adheres to the lighting and physics of both frames. This first-and-last-frame control mode remains exclusive to Veo 3.1 among major AI video models.
Audio represents one of the most significant differentiators between modern AI video models and their predecessors. Both Veo 3.1 and Seedance 2.0 generate audio natively alongside video, but they approach this challenge from different angles.
Veo 3.1's integrated audio generation creates synchronized soundtracks including dialogue, sound effects, and background music in a single pass through the model's architecture. This unified audio-visual generation ensures perfect temporal alignment between what viewers see and what they hear. The system understands context well enough to generate appropriate sounds—footsteps that match a character's gait, ambient noise that fits the environment, and music that complements the visual mood. Veo 3.1 remains especially strong for developers because it combines an official Google API with native audio generation.
The practical advantage of Veo 3.1's approach becomes evident in production workflows. For creators producing content where audio-visual coherence matters—commercials, social media content with voiceover, or narrative shorts—the native audio generation can save hours of post-production work per project. The audio isn't an afterthought added in post-processing; it's generated with full awareness of the visual content, resulting in tighter synchronization than most post-production workflows can achieve.
Seedance 2.0 takes a different approach through its reference-based audio system. Rather than generating audio from scratch based on scene understanding, the model can accept audio files as input and synchronize video generation to match the audio's rhythm, mood, and timing. This is particularly powerful for music videos, dance content, or any scenario where the audio track is predetermined and the video needs to match it precisely.
The model's beat-sync capability analyzes uploaded audio and generates video with movements, cuts, and visual elements that align with the music's rhythm. Combined with its multi-language lip-sync feature—which understands language-specific mouth shapes (visemes) and generates accurate lip movements for Chinese, English, and Spanish—Seedance 2.0 excels at creating digital human videos and character-driven content where precise audio-visual synchronization is critical.
The believability of AI-generated video hinges largely on how well the model understands and simulates real-world physics. Objects need to move with convincing weight and momentum, fabrics must drape naturally, fluids should behave like fluids, and interactions between objects must look plausible.
Both models have made significant strides in physics realism, but through different technical approaches. Seedance 2.0 incorporates enhanced physics-aware training objectives that penalize physically implausible motion during the generation process. In practice, that makes gravity, fabric drape, fluids, and object interactions look substantially more believable.
The improvement is particularly noticeable in scenarios involving complex motion—a dancer's clothing flowing naturally during movement, water splashing with realistic physics, or objects interacting with appropriate weight and momentum. For developers and creators, this matters because motion realism is the single biggest factor that determines whether AI-generated video crosses the threshold from "interesting demo" to "production-ready asset."
Veo 3.1 approaches physics realism through its cinema-grade rendering pipeline, which emphasizes natural motion blur, realistic lighting interactions, and sophisticated understanding of how cameras capture movement. The model's 24fps cinema-standard frame rate contributes to a film-like quality that feels more natural to viewers accustomed to professional video content. In practice, Veo 3.1 excels in cinematic lighting, textures, motion blur, and overall film-like realism.
OpenAI's Sora 2 still leads in pure physics simulation, but both Veo 3.1 and Seedance 2.0 have closed the gap significantly. For most practical applications—marketing content, social media videos, product demonstrations—both models deliver physics quality that meets professional standards.
Video duration represents a critical practical constraint in AI video generation. Longer durations enable more complex storytelling and reduce the need for stitching multiple clips together, but they also increase the technical challenge of maintaining consistency across frames.
Seedance 2.0 offers a significant advantage here with support for up to 20 seconds per generation. This extended duration provides substantially more room for narrative development, complex actions, and scene progression without requiring multiple generations. The model maintains consistency across this longer timeframe, addressing one of the persistent challenges in AI video where character appearance, object details, or scene elements would drift or change unexpectedly mid-clip.
Veo 3.1 caps generation at 8 seconds per clip, which requires creators working on longer content to generate multiple clips and stitch them together. However, the model compensates for this limitation with exceptional consistency within those 8 seconds and tools designed specifically for multi-clip workflows. The "Ingredients to Video" feature's improved consistency ensures that characters, backgrounds, and objects maintain their appearance across separate generations, making the stitching process more seamless.
For creators focused on short-form content—Instagram Reels, TikTok videos, YouTube Shorts—Veo 3.1's 8-second limit is less of a constraint. The model's native 9:16 vertical video support, released in the January 2026 update, specifically targets mobile-first, short-form video creation. This native vertical generation eliminates the need to crop horizontal video, preserving composition control and image quality.
Understanding the cost structure of AI video generation is essential for evaluating which model fits your budget and production volume. Both models offer multiple access tiers with significantly different pricing.
Veo 3.1 pricing varies considerably depending on the access platform and quality settings. Through Google AI Pro subscriptions ($19.99/month), the effective cost is approximately $0.16 per second based on the monthly credit allocation. API pricing through Vertex AI and Gemini API ranges from $0.10-0.15 per second for the Fast variant to $0.50-0.75 per second for the standard endpoint with full quality.
The Fast variant achieves 2x generation speed through algorithmic optimization with only a 1-8% quality trade-off, making it an excellent choice for draft iterations and high-volume social content. The standard variant delivers maximum quality for final production outputs. This two-tier system allows creators to optimize costs by using Fast mode for exploration and creative testing, then switching to standard mode for final deliverables.
Seedance 2.0 pricing remains officially unannounced as of February 2026, with the model still in limited beta access primarily through ByteDance's Jimeng AI platform. Current market estimates place it at roughly $0.60 per 10-second video at 2K resolution, which would position it competitively between mid-tier offerings if confirmed. The model is currently accessible for free through the Jimeng AI platform during the beta period, though production API access has not yet been officially launched.
For developers and businesses planning production deployments, Veo 3.1's mature API ecosystem through Google Cloud provides significant advantages in reliability, documentation, and integration support. Seedance 2.0's API availability remains limited, though unofficial API aggregation platforms have begun offering access.
The choice between Veo 3.1 and Seedance 2.0 often comes down to specific use case requirements. Here's how each model performs across common scenarios:
For High-End Commercial Production and Broadcast Content:
Veo 3.1 is the clear choice. The 4K resolution capability, cinema-grade color science, and professional lighting make it the only current AI model suitable for television commercials, cinema pre-rolls, and premium digital advertising where visual quality cannot be compromised. The broadcast-ready output requires minimal post-processing to meet professional standards.
For Social Media Content and Digital Marketing:
Both models excel here, but with different strengths. Veo 3.1's native vertical video support and fast generation mode make it ideal for high-volume social media production targeting Instagram, TikTok, and YouTube Shorts. Seedance 2.0's multimodal input system provides more creative control for brand-specific content where maintaining visual identity across multiple assets is critical.
For Music Videos and Rhythm-Synchronized Content:
Seedance 2.0 dominates this category. The ability to upload audio tracks and have the model generate video synchronized to the beat, combined with multi-language lip-sync capabilities, makes it purpose-built for music video creation, dance content, and any scenario where audio drives the visual rhythm.
For Product Demonstrations and E-Commerce:
Seedance 2.0's enhanced detail rendering excels at accurately reproducing product textures, logos, and packaging. The multimodal input allows merchants to upload product photos, demonstrate desired camera movements through reference videos, and generate professional showcase content quickly. Veo 3.1's precision and controlled pacing also work well for product videos emphasizing clean visuals and professional presentation.
For Narrative Storytelling and Character-Driven Content:
Seedance 2.0's 20-second duration and exceptional facial expression quality make it well-suited for narrative-driven videos with emotional resonance. The model's ability to maintain character consistency across longer clips reduces the technical challenges of multi-scene storytelling. Veo 3.1's character identity consistency across separate generations also works well for narrative content, though the 8-second limit requires more planning for scene sequencing.
For Developer Integration and Automated Workflows:
Veo 3.1's official Google API, comprehensive documentation, and enterprise-grade reliability make it the superior choice for developers building video generation into applications, products, or automated workflows. The API's maturity and Google Cloud integration provide the stability required for production deployments.
Beyond technical specifications, real-world production behavior matters just as much.
Veo 3.1 stands out for visual quality and cinematic feel. The 4K upscaling feature has opened new use cases for AI-generated video in professional contexts previously off-limits due to resolution constraints. The output looks professional and usually requires less post-processing than competing models. The native audio generation is contextually appropriate, though audio quality still varies with scene complexity.
Seedance 2.0 has generated significant enthusiasm for its multimodal control system. The model marks a clear jump from impressive demo to genuinely useful production tool. Its facial expression quality is a standout strength, and character animations feel more natural and less robotic than those of many competing models.
Generation speed represents a practical consideration in production workflows. Seedance 2.0's 30% speed improvement over its predecessor translates to faster iteration cycles, which matters significantly when exploring creative directions or generating high volumes of content. Veo 3.1's Fast mode provides similar speed advantages, though with the noted 1-8% quality trade-off.
Both models still exhibit occasional artifacts and errors common to AI video generation—physics violations, temporal inconsistencies, or unexpected visual elements. However, the frequency and severity of these issues have decreased substantially compared to earlier generation models. For most use cases, the error rate has fallen below the threshold where it prevents production use.
While this comparison focuses on Veo 3.1 and Seedance 2.0, understanding where they fit in the broader competitive landscape provides valuable context. OpenAI's Sora 2 remains the benchmark for pure physics realism, making it the preferred choice when objects need to interact with convincing physical accuracy. Kuaishou's Kling 3.0 offers native 4K at 60fps with excellent motion quality and a free tier, making it attractive for cost-conscious creators.
Many professional production teams use multiple models strategically—Seedance 2.0 for template-based work and content requiring multimodal control, Veo 3.1 for final high-quality deliverables requiring 4K resolution, and other models for specific strengths. The competitive landscape has matured to the point where model selection has become a strategic workflow decision rather than a search for a single "best" option.
Understanding the capabilities of Veo 3.1 and Seedance 2.0 is only valuable if you can actually access and use these models effectively. Veo4.im provides convenient access to multiple cutting-edge video and image generation models through a unified platform, eliminating the complexity of managing multiple API integrations and access points.
The platform allows creators, developers, and businesses to work with frontier AI models without the technical overhead of direct API integration. This unified access approach means you can test different models for specific use cases, switch between them based on project requirements, and optimize your workflow without being locked into a single vendor's ecosystem.
For teams evaluating which model best fits their production needs, having access to multiple options through a single interface dramatically reduces the friction of comparative testing. You can generate the same prompt across different models, compare results side-by-side, and make informed decisions based on actual output rather than theoretical specifications.
The rapid evolution of AI video generation in early 2026 shows that this category is still in the early stages of its development curve. Veo 3.1's achievement of 4K resolution and Seedance 2.0's multimodal architecture represent significant milestones, and they also point toward future capabilities that will further transform video production.
Expected developments in the near term include longer generation durations, improved physics simulation, better temporal consistency across extended clips, more sophisticated audio generation, and enhanced control systems that give creators even more precise influence over output. The competitive pressure between Google, ByteDance, OpenAI, and other players ensures rapid iteration and continuous improvement.
For creators and businesses, this means that investing in understanding these tools now—learning their strengths, limitations, and optimal use cases—provides a competitive advantage as the technology continues to mature. The workflows and creative approaches developed today will scale as the underlying models improve.
Veo 3.1 and Seedance 2.0 represent two different philosophies in AI video generation, both executed at a high level of technical sophistication. Veo 3.1 prioritizes maximum visual quality, cinematic polish, and professional-grade output suitable for the most demanding use cases. Seedance 2.0 emphasizes creative control, flexibility, and the ability to incorporate multiple reference sources into a unified generation.
Neither model is universally "better"—they excel in different scenarios and serve different creative needs. Veo 3.1 is the tool for creators who need broadcast-quality output and are willing to work within its constraints. Seedance 2.0 is the choice for creators who value control, flexibility, and the ability to direct the AI like a production assistant rather than simply prompting it.
The maturity of both models signals that AI video generation has crossed a critical threshold from experimental technology to production-ready tool. The question is no longer whether AI can generate usable video, but rather which model best fits your specific workflow, creative requirements, and production goals.
For convenient access to these and other cutting-edge AI video models, Veo4.im provides a unified platform that simplifies the complexity of working with multiple frontier models, allowing you to focus on creativity rather than technical integration.
Veo 3.1 vs Seedance 2: The Definitive 2026 AI Video Generation Comparison
Executive Summary: Which Model Wins?
Technical Specifications: A Side-by-Side Comparison
Resolution and Visual Quality: The 4K Advantage
The Multimodal Revolution: Seedance 2.0's Defining Feature
Audio Generation: Native Synchronization vs. Reference-Based Control
Physics Realism and Motion Quality
Duration and Temporal Consistency
Pricing and Accessibility
Use Case Analysis: Which Model for Which Scenario?